Migrating between GPFS filesystems with iRODS at KTH
This guest post is by Ilari Korhonen, Systems Manager at PDC Center for High Performance Computing, KTH Royal Institute of Technology, Stockholm, Sweden
Background
KTH needed to migrate data from a GPFS filesystem (which was in need of an on-disk format upgrade to 5.0.x) to another (GPFS) filesystem. The following steps were performed to create the target locations, register them with iRODS, replicate and then trim the data, and finally some confirmation of success.
Overview of host names:
| hostname(s) | role | architecture/OS |
|---|---|---|
snicirods-ems1 |
IBM ESS GPFS cluster management node | POWER8/LPAR/RHEL7 |
snicirods-gssio{1,2} |
IBM ESS GPFS cluster I/O nodes | POWER8/LPAR/RHEL7 |
walkingcatfish.pdc.kth.se |
GPFS iRODS resource server | x86-64/CentOS7 |
climbingcatfish.pdc.kth.se |
GPFS iRODS resource server | x86-64/CentOS7 |
capelin.pdc.kth.se |
iRODS Catalog Provider + DB server | x86-64/CentOS7 |
Preparation
First we created new filesets in the destination GPFS filesystem fs1
for the mirroring resources. As with the existing resources we set a
hard limit of 16 * 2^20 inodes and preallocate 64 * 2^10 of them.
[root@snicirods-ems1 ~]# for i in {0..3}; do mmcrfileset fs1 fs0resc$i -t "[MIRROR] iRODS Resource fs0resc$i" --inode-space new --inode-limit 16777216:65536; done
Fileset fs0resc0 created with id 12 root inode 3670019.
Fileset fs0resc1 created with id 13 root inode 33554435.
Fileset fs0resc2 created with id 14 root inode 34078723.
Fileset fs0resc3 created with id 15 root inode 34603011.
Once the filesets were created they could be mounted at the filesystem at the proper locations. We used a subpath of iRODS within both filesystems to mount the resource filesets. Other stuff was available in the root(s).
[root@snicirods-ems1 ~]# for i in {0..3}; do mmlinkfileset fs1 fs0resc$i -J /gpfs/fs1/iRODS/fs0resc$i; done
Fileset fs0resc0 linked at /gpfs/fs1/iRODS/fs0resc0
Fileset fs0resc1 linked at /gpfs/fs1/iRODS/fs0resc1
Fileset fs0resc2 linked at /gpfs/fs1/iRODS/fs0resc2
Fileset fs0resc3 linked at /gpfs/fs1/iRODS/fs0resc3
Then we listed all the filesets available in the GPFS
filesystem fs1 and double check.
[root@snicirods-ems1 ~]# mmlsfileset fs1 -L
Filesets in file system 'fs1':
Name Id RootInode ParentId Created InodeSpace MaxInodes AllocInodes Comment
root 0 3 -- Fri Feb 2 18:00:33 2018 0 134217728 500224 root fileset
resc0 1 524291 0 Tue Feb 13 15:56:04 2018 1 16777216 1523200 iRODS Resource fs1resc0
resc1 2 1048579 0 Tue Feb 13 15:56:05 2018 2 16777216 1523200 iRODS Resource fs1resc1
resc2 3 1572867 0 Tue Feb 13 15:56:06 2018 3 16777216 1523200 iRODS Resource fs1resc2
resc3 4 2097155 0 Tue Feb 13 15:56:08 2018 4 16777216 1523200 iRODS Resource fs1resc3
eudat 5 2621443 0 Tue Apr 17 13:34:44 2018 5 16777216 1904128 EUDAT iRODS Data Migration
snic1 6 3145731 0 Fri Jun 15 12:18:57 2018 6 16777216 3719680 SNIC iRODS Data Migration
fs0resc0 12 3670019 0 Tue Nov 12 17:37:47 2019 7 16777216 66048 [MIRROR] iRODS Resource fs0resc0
fs0resc1 13 33554435 0 Tue Nov 12 17:37:48 2019 8 16777216 66048 [MIRROR] iRODS Resource fs0resc1
fs0resc2 14 34078723 0 Tue Nov 12 17:37:49 2019 9 16777216 66048 [MIRROR] iRODS Resource fs0resc2
fs0resc3 15 34603011 0 Tue Nov 12 17:37:50 2019 10 16777216 66048 [MIRROR] iRODS Resource fs0resc3
Also, checking at the mount directory we could see that the mount points got created, which means that the filesets were present there.
[root@snicirods-ems1 ~]# ls -l /gpfs/fs1/iRODS/
total 0
drwx------ 3 3300044 3998996 4096 Apr 17 2018 eudat
drwx------ 2 root root 4096 Nov 12 17:39 fs0resc0
drwx------ 2 root root 4096 Nov 12 17:39 fs0resc1
drwx------ 2 root root 4096 Nov 12 17:39 fs0resc2
drwx------ 2 root root 4096 Nov 12 17:39 fs0resc3
drwx------ 3 3300044 3998996 4096 Feb 13 2018 resc0
drwx------ 3 3300044 3998996 4096 Feb 13 2018 resc1
drwx------ 3 3300044 3998996 4096 Feb 13 2018 resc2
drwx------ 3 3300044 3998996 4096 Feb 13 2018 resc3
drwx------ 3 3300044 3998996 4096 Jun 15 2018 snic1
In preparation for iRODS usage, we set permissions to irods:irods and
created a Vault directory for general cleanliness.
walkingcatfish# for i in {0..3}; do chown irods:irods /gpfs/fs1/iRODS/fs0resc$i; done
walkingcatfish# for i in {0..3}; do mkdir /gpfs/fs1/iRODS/fs0resc$i/Vault; done
walkingcatfish# for i in {0..3}; do chown irods:irods /gpfs/fs1/iRODS/fs0resc$i/Vault; done
Then we checked that the Vault directories were available with the correct POSIX permissions for iRODS use.
walkingcatfish# for i in {0..3}; do ls -ld /gpfs/fs1/iRODS/fs0resc$i/Vault; done
drwxr-xr-x 2 irods irods 4096 Nov 12 17:43 /gpfs/fs1/iRODS/fs0resc0/Vault
drwxr-xr-x 2 irods irods 4096 Nov 12 17:43 /gpfs/fs1/iRODS/fs0resc1/Vault
drwxr-xr-x 2 irods irods 4096 Nov 12 17:43 /gpfs/fs1/iRODS/fs0resc2/Vault
drwxr-xr-x 2 irods irods 4096 Nov 12 17:43 /gpfs/fs1/iRODS/fs0resc3/Vault
First step in the reorganization of our iRODS resources was of course to take
out the GPFS fs0-based resources from the tree to which we point our
users, in order to prevent additional puts to those resources.
walkingcatfish$ iadmin rmchildfromresc pdc-gpfs-random0 pdc-gpfs-fs0-random0
Then looking at the resource tree passed through to the users virtually
as pdc-gpfs we could see that all the resources were prefixed with fs1.
walkingcatfish$ ilsresc pdc-gpfs
pdc-gpfs:passthru
└── pdc-gpfs-random0:random
└── pdc-gpfs-fs1-random0:random
├── fs1resc0:unixfilesystem
├── fs1resc1:unixfilesystem
├── fs1resc2:unixfilesystem
└── fs1resc3:unixfilesystem
Additionally, the fs0-half of the GPFS resource tree was now
stand-alone and still accessible, but not by default.
walkingcatfish$ ilsresc pdc-gpfs-fs0-random0
pdc-gpfs-fs0-random0:random
├── fs0resc0:unixfilesystem
├── fs0resc1:unixfilesystem
├── fs0resc2:unixfilesystem
└── fs0resc3:unixfilesystem
New Target Resources
Time to create new resources, to mirror the resources in the GPFS
filesystem fs0, hosted now in the other filesystem fs1.
walkingcatfish$ for i in {0..3}; do iadmin mkresc fs1-fs0resc$i unixfilesystem climbingcatfish.pdc.kth.se:/gpfs/fs1/iRODS/fs0resc$i; done
Creating resource:
Name: "fs1-fs0resc0"
Type: "unixfilesystem"
Host: "climbingcatfish.pdc.kth.se"
Path: "/gpfs/fs1/iRODS/fs0resc0"
Context: ""
Creating resource:
Name: "fs1-fs0resc1"
Type: "unixfilesystem"
Host: "climbingcatfish.pdc.kth.se"
Path: "/gpfs/fs1/iRODS/fs0resc1"
Context: ""
Creating resource:
Name: "fs1-fs0resc2"
Type: "unixfilesystem"
Host: "climbingcatfish.pdc.kth.se"
Path: "/gpfs/fs1/iRODS/fs0resc2"
Context: ""
Creating resource:
Name: "fs1-fs0resc3"
Type: "unixfilesystem"
Host: "climbingcatfish.pdc.kth.se"
Path: "/gpfs/fs1/iRODS/fs0resc3"
Context: ""
Double checking with ilsresc we could see what we just did.
climbingcatfish$ for i in {0..3}; do ilsresc -l fs1-fs0resc$i | egrep "name|location|vault"; done
resource name: fs1-fs0resc0
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc0
resource name: fs1-fs0resc1
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc1
resource name: fs1-fs0resc2
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc2
resource name: fs1-fs0resc3
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc3
Which turned out to be wrong, the vault locations needed to be fixed.
climbingcatfish$ for i in {0..3}; do iadmin modresc fs1-fs0resc$i path /gpfs/fs1/iRODS/fs0resc$i/Vault; done
Level 0: Previous resource path: /gpfs/fs1/iRODS/fs0resc0
Level 0: Previous resource path: /gpfs/fs1/iRODS/fs0resc1
Level 0: Previous resource path: /gpfs/fs1/iRODS/fs0resc2
Level 0: Previous resource path: /gpfs/fs1/iRODS/fs0resc3
And then, it seemed we had what we wanted.
climbingcatfish$ for i in {0..3}; do ilsresc -l fs1-fs0resc$i | egrep "name|location|vault"; done
resource name: fs1-fs0resc0
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc0/Vault
resource name: fs1-fs0resc1
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc1/Vault
resource name: fs1-fs0resc2
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc2/Vault
resource name: fs1-fs0resc3
location: climbingcatfish.pdc.kth.se
vault: /gpfs/fs1/iRODS/fs0resc3/Vault
Migrating Data with the Delay Queue
After a few initial test replication runs into the mirroring resources, we had a session with Jason Coposky and Terrell Russell about a rule which puts replication jobs into the delayed rule execution queue. The following iRODS rule script was borne out based on that discussion.
This rule enables us to invoke as much parellelism as possible from the iRODS delayed rule execution server and run several replication and checksumming jobs in parallel.
syncRescAtPath
{
# get all object replicas present at source and loop over
foreach (*row0 in SELECT COLL_NAME, DATA_NAME WHERE COLL_NAME LIKE '*collPath%' AND DATA_RESC_NAME = '*sourceRescName')
{
*skipObj = 0;
*collName = *row0.COLL_NAME;
*dataName = *row0.DATA_NAME;
*objPath=*row0.COLL_NAME++"/"++*row0.DATA_NAME;
# loop over resources where data object is present
foreach (*row1 in SELECT DATA_RESC_NAME WHERE COLL_NAME = *collName AND DATA_NAME = *dataName)
{
# we skip this object if present at target
if (*row1.DATA_RESC_NAME == *targetRescName)
{
*skipObj = 1;
writeLine("stdout", "*sourceRescName -> *targetRescName: skipping object path '*objPath'");
}
}
# otherwise we enqueue a replication job for this object
if (*skipObj == 0)
{
writeLine("stdout", "*sourceRescName -> *targetRescName: enqueue replication job for object path '*objPath'");
delay("<PLUSET>0m</PLUSET>")
{
msiDataObjRepl(*objPath, "rescName=*sourceRescName++++destRescName=*targetRescName++++irodsAdmin=", *status);
writeLine("serverLog", "ASYNC: syncRescAtPath: *sourceRescName -> *targetRescName: replicated objPath '*objPath', status=*status");
}
}
}
}
INPUT *sourceRescName="fs0resc0", *targetRescName="fs1-fs0resc0", *collPath="/snic.se/projects/operations"
OUTPUT ruleExecOut
We also set the number of concurrent rule execution server threads to
a count of 16 and sleep to 1 sec in /etc/irods/server_config.json or
as it is described in our Ansible variables:
irods_server_config:
advanced_settings:
maximum_number_of_concurrent_rule_engine_server_processes: 16
rule_engine_server_sleep_time_in_seconds: 1
This rule was first tested against our test projects
/snic.se/projects/{operations,ops,test} and later run 'en masse'
against the whole set of live research projects in SNIC iRODS.
climbingcatfish$ for proj in blaah; do for i in {0..3}; do irule -F syncRescAtPath.r "*sourceRescName='fs0resc${i}'" "*targetRescName='fs1-fs0resc${i}'" \
"*collPath='/snic.se/projects/${proj}'" | tee syncRescAtPath-projects-${proj}-fs0resc${i}-$(date --iso-8601=seconds).txt; done; done
However, the first tests revealed that the Catalog Service Provider machine couldn't handle the 16 threads and 1 sec of sleep time. Errors like the following started surfacing in the rodsLog very repeatedly.
Nov 16 17:32:40 pid:27246 remote addresses: 127.0.0.1 ERROR: cllConnect: SQLConnect failed: -1
Nov 16 17:32:40 pid:27246 remote addresses: 127.0.0.1 ERROR: cllConnect: SQLConnect failed:odbcEntry=iRODS Catalog,user=irods,pass=XXXXX
Nov 16 17:32:40 pid:27246 remote addresses: 127.0.0.1 ERROR: cllConnect: SQLSTATE: 08001
Nov 16 17:32:40 pid:27246 remote addresses: 127.0.0.1 ERROR: cllConnect: Native Error Code: 101
Nov 16 17:32:40 pid:27246 remote addresses: 127.0.0.1 ERROR: cllConnect: [unixODBC]FATAL: remaining connection slots are reserved for non-replication superuser connections
After this I cleared the rule exec queue and reset the configuration variables to 8 threads and 5 sec of sleep time, to be more cautious.
irods_server_config:
advanced_settings:
maximum_number_of_concurrent_rule_engine_server_processes: 8
rule_engine_server_sleep_time_in_seconds: 5

Even after this change, after scheduling enough replication jobs into
the rule execution queue, the number of irodsServer processes and
associated DB connections rose to quite a high number, hovering around
1000 processes/connections at the catalog server.
ICAT=# select count(*) from pg_stat_activity;
count
-------
1019
(1 row)
capelin$ ps aux | grep irodsServer | wc -l
1021
Sometimes the same database errors as documented above appeared again, but the system handled it somewhat well, perhaps due to successfully retrying the DB connection and then succesfully executing the delayed job in question.
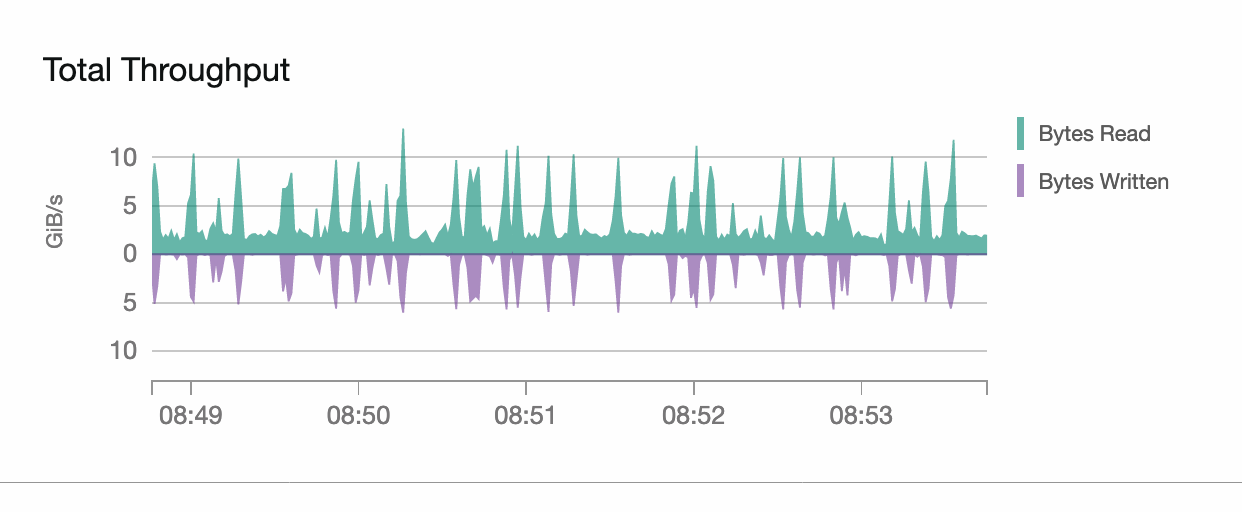
However, in one project, 2 objects failed.
Nov 16 23:36:10 pid:23718 NOTICE: dataCreate: l3Create of /gpfs/fs1/iRODS/fs0resc3/Vault/projects/icos/[path1] failed, status = -38000
Nov 16 23:36:10 pid:23718 NOTICE: dataCreate: l3Create of /gpfs/fs1/iRODS/fs0resc3/Vault/projects/icos/[path1] failed, status = -38000
Nov 16 23:36:10 pid:23718 DEBUG: msiDataObjRepl: rsDataObjRepl failed /snic.se/projects/icos/[path1], status = -38000
caused by: DEBUG: msiDataObjRepl: rsDataObjRepl failed /snic.se/projects/icos/[path1], status = -38000
Nov 16 23:36:11 pid:23718 NOTICE: dataCreate: l3Create of /gpfs/fs1/iRODS/fs0resc3/Vault/projects/icos/[path2] failed, status = -38000
Nov 16 23:36:11 pid:23718 NOTICE: dataCreate: l3Create of /gpfs/fs1/iRODS/fs0resc3/Vault/projects/icos/[path2] failed, status = -38000
Nov 16 23:36:11 pid:23718 DEBUG: msiDataObjRepl: rsDataObjRepl failed /snic.se/projects/icos/[path2], status = -38000
caused by: DEBUG: msiDataObjRepl: rsDataObjRepl failed /snic.se/projects/icos/[path2], status = -38000
These failed objects were scheduled for replication again later and successfully replicated without incident.
$ for file in syncRescAtPath-projects-icos-fs0resc*2019-11-18*.txt.gz; do zcat $file | grep -v skipping; done
fs0resc3 -> fs1-fs0resc3: enqueue replication job for object path '/snic.se/projects/icos/[path1]'
fs0resc3 -> fs1-fs0resc3: enqueue replication job for object path '/snic.se/projects/icos/[path2]'
After the project replication jobs were finished, the stats for the object counts were queried per project and logged into a file.
climbingcatfish$ iquest "%s" "select COLL_NAME where COLL_PARENT_NAME = '/snic.se/projects'" | while read objpath; do for resc in {fs1-,}fs0resc{0..3}; do iquest "object count (${resc}/${objpath}): %s" "select count(DATA_ID) where COLL_NAME like '${objpath}%' and DATA_RESC_NAME = '${resc}'"; done; echo "---"; done | tee snic.se-projects-objcounts-$(date --iso-8601=seconds).txt
The final stage was to replicate all the remaining objects in the zone
snic.se from the fs0-based resources into fs1. For
this a rather wide replication job was invoked.
climbingcatfish$ for i in {0..3}; do irule -F syncRescAtPath.r "*sourceRescName='fs0resc${i}'" "*targetRescName='fs1-fs0resc${i}'" "*collPath='/snic.se/'" | tee syncRescAtPath-snic.se-fs0resc${i}-$(date --iso-8601=seconds).txt; done
After this run was finished, there was still one object missing from
the resources at fs1.
climbingcatfish$ for resc in {fs1-,}fs0resc{0..3}; do iquest "object count (${resc}): %s" "select count(DATA_ID)' WHERE DATA_RESC_NAME = '${resc}'"; done
object count (fs1-fs0resc0): 836916
object count (fs1-fs0resc1): 836576
object count (fs1-fs0resc2): 834842
object count (fs1-fs0resc3): 836643
object count (fs0resc0): 836917
object count (fs0resc1): 836576
object count (fs0resc2): 834842
object count (fs0resc3): 836643
The missing object was located by querying via GenQuery, and simply deleted due to being an orphan object of a test file by yours truly.
climbingcatfish$ iquest "%s/%s" "select COLL_NAME, DATA_NAME where DATA_RESC_NAME = 'fs0resc0'" --no-page | sort > fs0resc0-objpaths.txt
climbingcatfish$ iquest "%s/%s" "select COLL_NAME, DATA_NAME where DATA_RESC_NAME = 'fs1-fs0resc0'" --no-page | sort > fs1-fs0resc0-objpaths.txt
climbingcatfish$ diff fs0resc0-objpaths.txt fs1-fs0resc0-objpaths.txt
climbingcatfish$ echo $?
1
climbingcatfish$ irm -f /snic.se/trash/orphan/rods#snic.se/bigfile.2151629042
climbingcatfish$ iquest "%s/%s" "select COLL_NAME, DATA_NAME where DATA_RESC_NAME = 'fs0resc0'" --no-page | sort > fs0resc0-objpaths.txt
climbingcatfish$ iquest "%s/%s" "select COLL_NAME, DATA_NAME where DATA_RESC_NAME = 'fs1-fs0resc0'" --no-page | sort > fs1-fs0resc0-objpaths.txt
climbingcatfish$ diff fs0resc0-objpaths.txt fs1-fs0resc0-objpaths.txt
climbingcatfish$ echo $?
0
After this the resources in fs0 and the mirroring resources at fs1
were fully in balance.
climbingcatfish$ for resc in {fs1-,}fs0resc{0..3}; do iquest "object count (${resc}): %s" "select count(DATA_ID) where DATA_RESC_NAME = '${resc}'"; done
object count (fs1-fs0resc0): 836916
object count (fs1-fs0resc1): 836576
object count (fs1-fs0resc2): 834842
object count (fs1-fs0resc3): 836643
object count (fs0resc0): 836916
object count (fs0resc1): 836576
object count (fs0resc2): 834842
object count (fs0resc3): 836643
climbingcatfish$
Trimming Original Replicas
Time to trim down the resources at filesystem fs0. For this I wrote a
similar rule to the previous one, which simply loops over all the
objects present at the resource and schedules trim jobs for those.
trimRescAtPath
{
# get all object replicas present at source and loop over
foreach (*row in SELECT COLL_NAME, DATA_NAME WHERE COLL_NAME LIKE '*collPath%' AND DATA_RESC_NAME = '*sourceResc')
{
*collName = *row.COLL_NAME;
*dataName = *row.DATA_NAME;
*objPath=*row.COLL_NAME++"/"++*row.DATA_NAME;
writeLine("stdout", "*sourceResc: enqueue trim job for object path '*objPath'");
delay("<PLUSET>0m</PLUSET>")
{
msiDataObjTrim(*objPath, *sourceResc, "null", "2", "irodsAdmin", *status);
writeLine("serverLog", "ASYNC: trimRescAtPath: *sourceResc: trimmed objPath '*objPath', status=*status");
}
}
}
INPUT *sourceResc="fs0resc0", *collPath="/snic.se/projects/operations"
OUTPUT ruleExecOut
Using this rule the trim jobs were executed, for one subcollection of
snic.se at a time, to be conservative, and finally for the entirety of
the snic.se zone.
climbingcatfish$ for i in {0..3}; do irule -F trimRescAtPath.r "*sourceResc='fs0resc${i}'" "*collPath='/snic.se/home'"; done | tee trimRescAtPath-fs0resc${i}-home-$(date --iso-8601=seconds).txt
climbingcatfish$ for i in {0..3}; do irule -F trimRescAtPath.r "*sourceResc='fs0resc${i}'" "*collPath='/snic.se/migration'"; done | tee trimRescAtPath-fs0resc${i}-migration-$(date --iso-8601=seconds).txt
climbingcatfish$ for i in {0..3}; do irule -F trimRescAtPath.r "*sourceResc='fs0resc${i}'" "*collPath='/snic.se/projects'"; done | tee trimRescAtPath-fs0resc${i}-projects-$(date --iso-8601=seconds).txt
climbingcatfish$ for i in {0..3}; do irule -F trimRescAtPath.r "*sourceResc='fs0resc${i}'" "*collPath='/snic.se/'"; done | tee trimRescAtPath-fs0resc${i}-snic.se-$(date --iso-8601=seconds).txt
After the trim jobs were finished, the remaining object counts were queried from the database, revealing that a few remained.
climbingcatfish$ for resc in fs0resc{0..3}; do iquest "object count (${resc}): %s" "select count(DATA_ID) where DATA_RESC_NAME = '${resc}'"; done
object count (fs0resc0): 102
object count (fs0resc1): 94
object count (fs0resc2): 102
object count (fs0resc3): 102
The identities of those remaining objects were then dumped into respective files per resource.
climbingcatfish$ for resc in fs0resc{0..3}; do iquest "%s/%s" "select COLL_NAME, DATA_NAME where RESC_NAME = '${resc}'" > objpaths-${resc}-$(date --iso-8601=seconds).txt; done
By removing all the leftover paths that were in
/snic.se/trash we can check which objects were missed by the trim jobs.
$ for file in objpaths-fs0resc*; do grep -v /snic.se/trash $file; done
/snic.se/home/ilarik/pdcfw-0.1.2-2.noarch.rpm
/snic.se/home/ilarik.admin/pdcfw-0.1.1-2.noarch.rpm
[...]
These were rescheduled for trimming and cleaned up without incident. A smarter retry mechanism could have cleaned them up automatically.
Conclusion
iRODS allowed KTH to nearly seamlessly migrate over 3 million data objects from a GPFS filesystem that was in need of a reformat to a newly created GPFS filesystem. The system was not required to be down, and users never had any interruption to their service or their files.
Future improvements could be made to the connection pooling and retry mechanisms within iRODS. These are both now in the development roadmap and should be available soon.
Ilari Korhonen, Terrell Russell