Frequently Asked Questions
General
How does iRODS handle metadata and data discovery
One of the primary functions of iRODS is to connect unstructured data with metadata. Metadata may be attached to files, users, groups, collections (iRODS equivalent of sub-directories), and resources (data containers [e.g., a hard drive]).Each iRODS zone contains an iCAT-enabled resource server (“iCAT server” for short), which uses a relational database to organize the content of the zone and to maintain iRODS metadata.
The iCAT server stores metadata in the form of “triples” to its relational database. The triples consist of an attribute field, a value field, and a unit field. The content of each of these fields can be independently defined and applied. Metadata may be user-defined or applied automatically. By default, iRODS does not automatically apply any user-accessible metadata; the zone administrator must implement metadata automation in the iRODS rule engine.
Once metadata is applied, it can be used in various ways. It can be used to trigger actions, based on rules defined in the iRODS rule engine.
iRODS metadata can be searched as well. A simple way to search is using the iRODS imeta command. More complex queries can be generated using a subset of SQL operations issued through the iquest command.
A search capability based on file contents has been implemented in an experimental capacity. We will release details as they become available.
How many lines of code is iRODS
iRODS is roughly 250k lines of C++.What are the system requirements for iRODS
We recommend a system with at least 2 GB of RAM for an iCAT server. The actual iRODS packages require less than 100 MB of disk space. However, dependencies may require extra space.In a production environment, the relational database will most likely reside on one or more servers, separate from the iCAT server. Refer to the documentation for the database for advice on sizing the database server. In general, as the size and access rate of the database increase, more RAM and processor cores will be required for acceptable performance.
What operating systems can be used with iRODS
The most current list of OSes that we test against is available at irods.org/download/. iRODS can also be compiled for other POSIX OSes, but they may not be included in our continuous integration and testing,Try it out: Clone from our GitHub repository at github.com/irods/irods
What is the advantage of having iRODS or any other low level storage management
What are its benefits
When should iRODS be used
Don’t think of iRODS as low level storage management.iRODS is really the only platform for policy managed data preservation. It does indeed virtualize storage, providing a global, logical namespace over heterogeneous types of storage, but it also allows you to enforce preservation policies at each storage location, no matter what client or access method is used. It also provides a global metadata catalog that is automatically maintained and reflects the application of your preservation policies, allowing audit and verification of your preservation policies.
iRODS is developing a powerful metadata management capability, allowing pluggable indexing and query capability that allow synchronization with external indices (e.g. Elastic Search, MAUI, Jena triple store).
With the pluggable rule engine and asynchronous messaging architecture, it becomes rather straightforward to generate audit and provenance metadata that will track every single (pre- and post-) operation on your data, including any plugins you may develop or utilize.
iRODS is middleware, rather than a prepackaged solution. This middleware supports plugins and configurable policies at all points, so you are not limited by a pre-defined set of tools. iRODS also can be connected to wide range of preservation, computation, and enterprise services, and can manage large amounts of data (both in number of objects and size of those objects), and efficiently move and manage data using high performance protocols, including third party data transfer protocols.
iRODS is built to support federation, so that your preservation environment may share data with other institutions or organizations while remaining under your own audit and policy control. Many organizations are doing this for many millions of objects, many thousands of users, and with a large range of object sizes.
Database
What database software can be used with iRODS
The most current list of DBMSes that we test against is available at irods.org/download/.Can I set up an iCAT server and a resource server on the same machine
Every iCAT server is also a resource server. In fact, “iCAT server” is shorthand for “iCAT-enabled resource server”. As such, the resource server package can not be installed on the same machine as the iCAT server package.Why do I need to set up a separate database? I thought iRODS was data management software
iRODS manages unstructured data. Generally, this means files, but iRODS can manage other types of data as well. This is data that doesn’t fit directly into the relational database paradigm. However, iRODS makes extensive use of a relational database to link unstructured data to metadata. We recognize that there already exist several very capable relational databases. So, iRODS works with your choice of a number of prominent, externally-developed relational databases.How do I set up an iCAT server with a remote
Postgres database
Configuring iRODS to work with a remote database is exactly the same as configuring iRODS to work with a local database.
The iRODS setup script asks for database configuration information and one of the prompts is for database host. When the database server is on the same machine as the iRODS server, the answer is usually ‘localhost’.
When the database server is on a different machine, the answer is usually the fully qualified domain name (FQDN) of the machine hosting the database.
Performance
How does iRODS transfer performance compare
with FTP or other protocol
For files larger than 32MB (by default, but configurable), iRODS uses multiple threads to transfer data in parallel. This provides iRODS with a significant speed advantage over FTP, which only uses a single thread for transfers. For transferring large files, iRODS can be comparable or even faster than GridFTP. Download 2010-ntnu-irods_performance.pdf from NTNU.
Additional networking performance information can be found in our 2016 performance whitepaper.
How many petabytes/files/users can iRODS manage
How do I scale iRODS to handle my data
What are you doing to make sure iRODS continues to scale
CC-IN2P3 is hosting 80M files on iRODS at a peak access rate of 800k files per day. The iPlant collaborative uses iRODS to server over 110M files, nearly 1PB, to over 20k users. The Wellcome Trust Sanger Institute uses iRODS to host over 24PB of data, replicated to make nearly 48 PB of data.There are specific adaptations the above institutions have made to their iRODS configurations to operate at scale. To understand how these adaptations work, consider the following diagram of a small iRODS deployment.
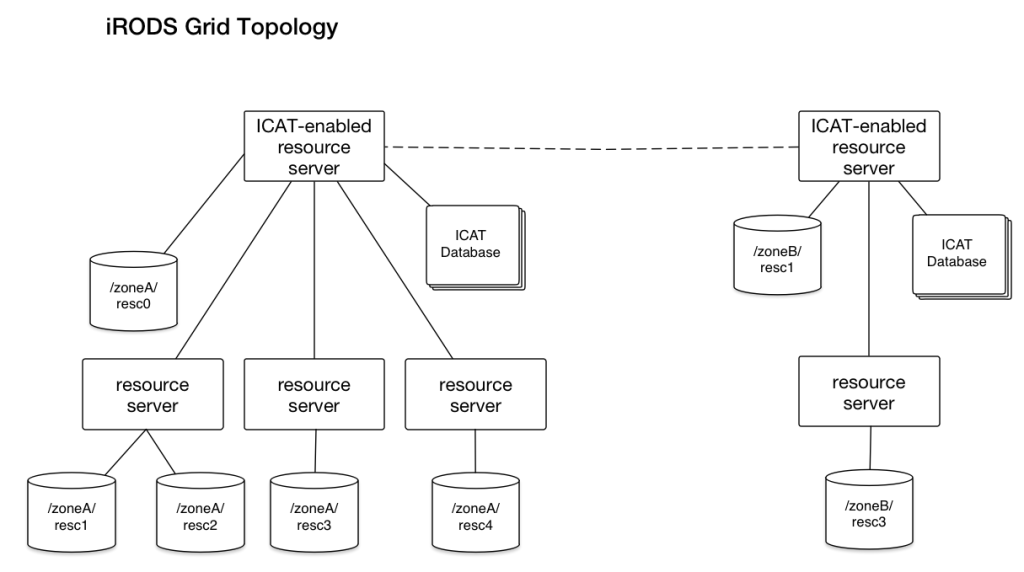
Potential bottlenecks exist wherever a workload is not distributed over multiple services. Most efforts to prepare iRODS for scalability focus on distributing the load on the ICAT-enabled server (IES) or the ICAT database. Three methods have been identified to provide this load distribution: zone segmentation, database load balancing, and round-robin DNS.
Zone Segmentation
One way to lessen the load on an IES and ICAT database is to divide the deployment into multiple administrative zones. Because iRODS can connect multiple zones through federation, users logged into zoneA can access files stored on zoneB using their zoneA login credentials.Drawbacks: Federation is not completely seamless. Separate zones can have separate sets of policies and separate sets of users. This is extraordinarily flexible, because federation is meant to permit completely separate organizations to share data. But it also increases the complexity of the system, particularly if one person is responsible for administering all the zones. Another limitation of this approach is that metadata does not get transferred when files are copied between zones.
Read more about iRODS Federation.
Database Load Balancing
The ICAT database is critically important for the operation of a zone. All three of the presently supported database management systems (DBMS)–PostgreSQL, MySQL, and Oracle–have load balancing capabilities available, through pgpool, HAProxy, or Oracle RAC, respectively. A load-balanced database appears the same to iRODS as an ordinary database, so no additional configuration of iRODS is necessary.Consult the support resources for the load balancing system of your specific DBMS for more information.
Round-Robin DNS
A third technique used to scale iRODS deployments is to use round-robin DNS with multiple IES servers. In this configuration, the IES servers are replicas of one another, and they are all connected to the same ICAT database, which may be configured with its own load balancing scheme. The DNS server is configured to resolve addresses such that requests are distributed between the IES servers.Consult the documentation for your DNS server (or an alternative, similar high availability solution) for more information about this approach.
Future iRODS Architecture
The solutions discussed above are techniques that have been proven to work when deploying iRODS at scale. The iRODS Consortium is also investigating the use of nontraditional (e.g., NoSQL) databases as a means of scaling the ICAT database to handle a massive number of records. However, significant architectural changes are required to make this possible.Alternative database technologies and other iRODS improvements are topics of active discussion at iRODS Consortium Technology Working Group meetings, which bring together Consortium members each month to discuss technical issues and roadmaps for iRODS.
Future
What are some future directions for iRODS development
What is the current iRODS roadmap
Please see GitHub for the technical iRODS roadmap for upcoming releases, and the status of particular issues. The long term technical vision for iRODS includes features such as:API Consistency across Programming Languages: Leverage existing technologies such as Apache Avro to provide a thinner, unified platform from which numerous client side development libraries may be created, including APIs for clients built in java, python, PHP and more. This effort will relieve development pressure to ensure sustainability and compatibility into the future.
Zone Introspection: Currently a client has no way to know what capabilities a particular iRODS zone can provide, which servers are running and healthy, and which plugins are installed and enabled. Zone introspection, introduced for iRODS 4.0.3 and beyond through the zonereport plugins, will provide this information. This capability simplifies zone administration and troubleshooting, and eventually a client may be able to request certain features from the grid and be routed to an appropriate server to provide those capabilities.
Plugin Bundles: As plugins become more complicated and new features emerge that span many plugins, a dependency model will need to be put into place to allow the enforcement of plugin dependencies. A plugin bundle represents a package of dependent plugins which might represent a new feature to iRODS. This ties directly into zone introspection, as this tool will help the zone administrator manage those dependencies.
Indexing Framework ( External Service Integration ): An iRODS indexing framework will provide the ability to do full-content indexing of data stored in an iRODS zone. We are working to package the products of this DFC-led effort for straightforward and reliable deployment. This technology will enable a robust discovery environment in the short term and other services such as auditing in the future.