Supercomputing 2018


iRODS: Managing Data from the Edge to HPC
Data management has historically started at the point of ingest where users manually placed data into a system. While this process was sufficient for a while, the volume and velocity of automatically created data coming from sequencers, satellites, and microscopes have overwhelmed existing systems. In order to meet these new requirements, the point of ingest must be moved closer to the point of data creation.
iRODS now supports packaged capabilities which implement the necessary automation to scale ingest horizontally. This shifts the application of data management policy directly to the edge.
Once your data resides in the iRODS namespace, additional capabilities such as storage tiering, data integrity, and auditing may be applied. This includes tiering data to scratch storage for analysis, archiving, and collaboration. The combination of these capabilities plus additional policy allow for the implementation of the data to compute pattern which can tailored to meet your specific use cases.
Monday, November 12, 2018
8:30 - 11:00 a.m. CT
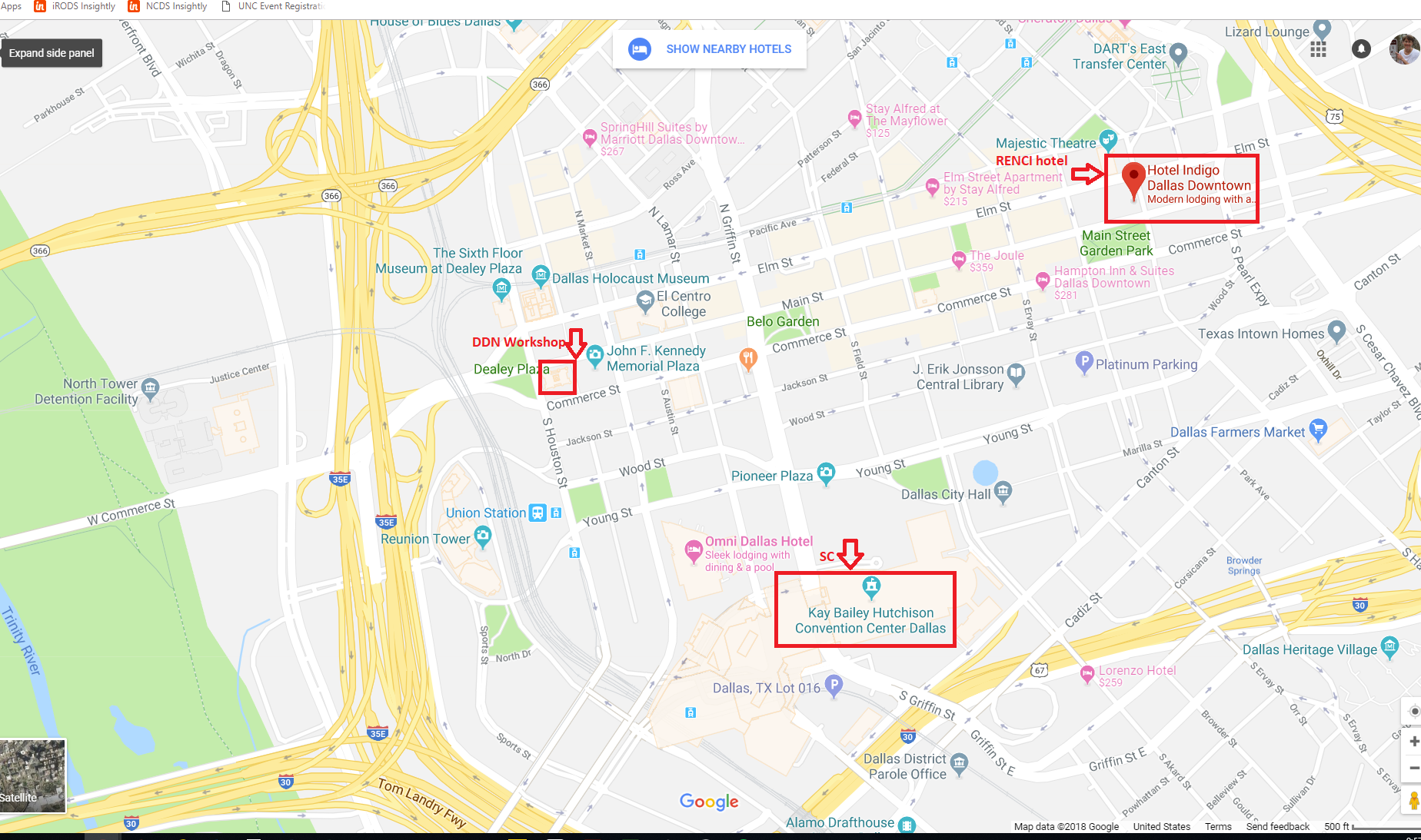
Restoration Room
Old Red Museum of Dallas County History and Culture
100 Houston Street
Dallas, TX 75202
View Map
{kind=link}