Documentation
Overview and Training Materials
Technical Documentation
Technical Diagrams
The following series of technical one-pagers tell a story, starting with the iRODS Data Management Model.
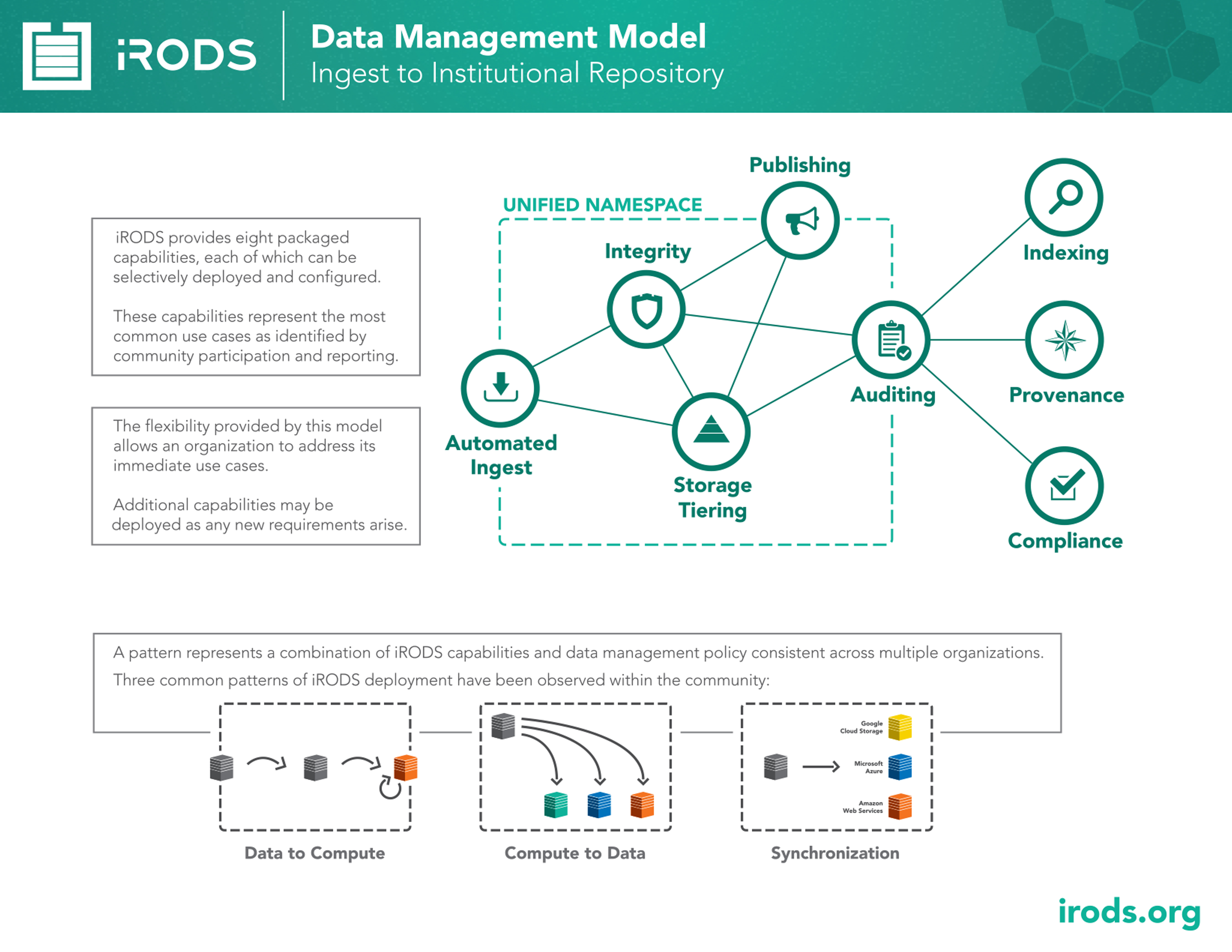
iRODS: Data Management Model
iRODS provides eight packaged capabilities, each of which can be selectively deployed and configured (usually into known patterns). These patterns and capabilities represent the most common use cases as identified by community participation and reporting.
iRODS provides eight packaged capabilities, each of which can be selectively deployed and configured (usually into known patterns). These patterns and capabilities represent the most common use cases as identified by community participation and reporting.
The model contains eight capabilities which can be combined into interesting patterns:
- Data to Compute is Automated Ingest + Tiering + Additional Policy
- Compute to Data is Sorting Policy + Job Routing Policy
- Synchronization is Automated Ingest + Sync Policy
- Data Transfer Nodes is Cache Management Policy + Replication Policy
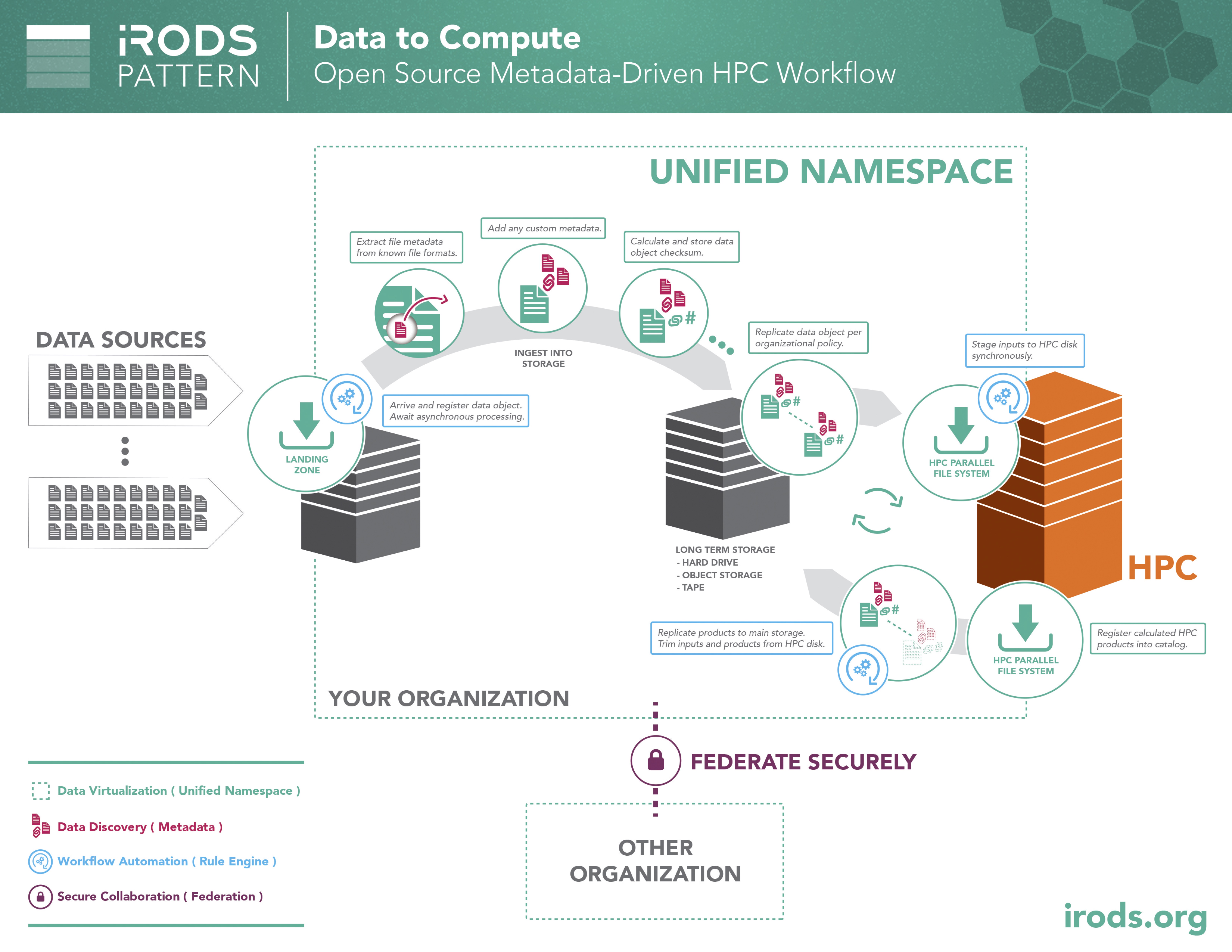
Pattern: Data to Compute
In many existing enterprise and research deployments, HPC clusters are separated from long term data storage technologies. When data needs to be moved to HPC and back again, the Data to Compute design pattern can leverage metadata-driven workflows and automate the execution of an organization's data management policy.
In many existing enterprise and research deployments, HPC clusters are separated from long term data storage technologies. When data needs to be moved to HPC and back again, the Data to Compute design pattern can leverage metadata-driven workflows and automate the execution of an organization's data management policy.
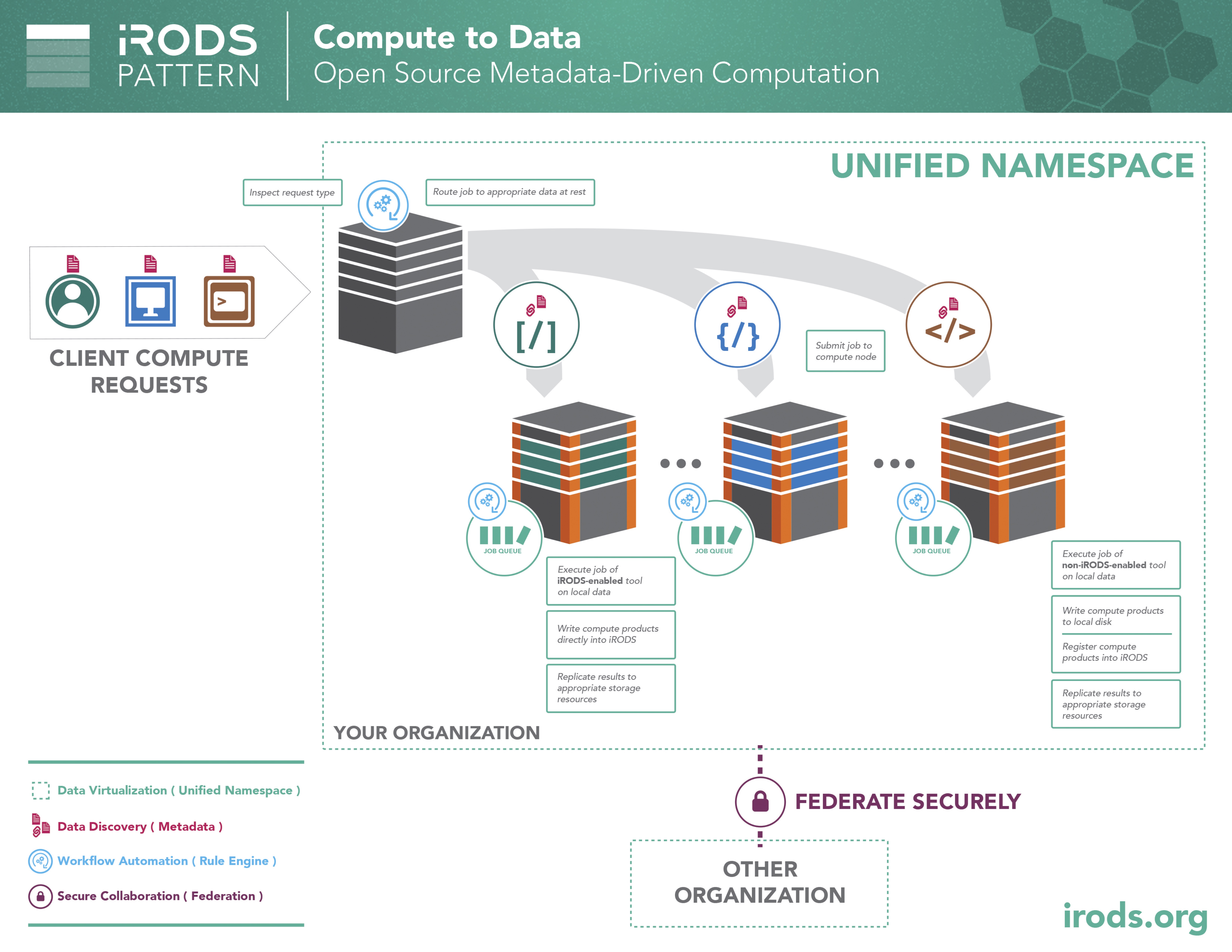
Pattern: Compute to Data
When data is stored in specific locations due to a requirement for specialized software or hardware or only because it is too big and expensive to move, compute requests can be routed to the appropriate location automatically. This metadata-driven computation design pattern could serve as a bridge until the time services are more fully containerized.
When data is stored in specific locations due to a requirement for specialized software or hardware or only because it is too big and expensive to move, compute requests can be routed to the appropriate location automatically. This metadata-driven computation design pattern could serve as a bridge until the time services are more fully containerized.
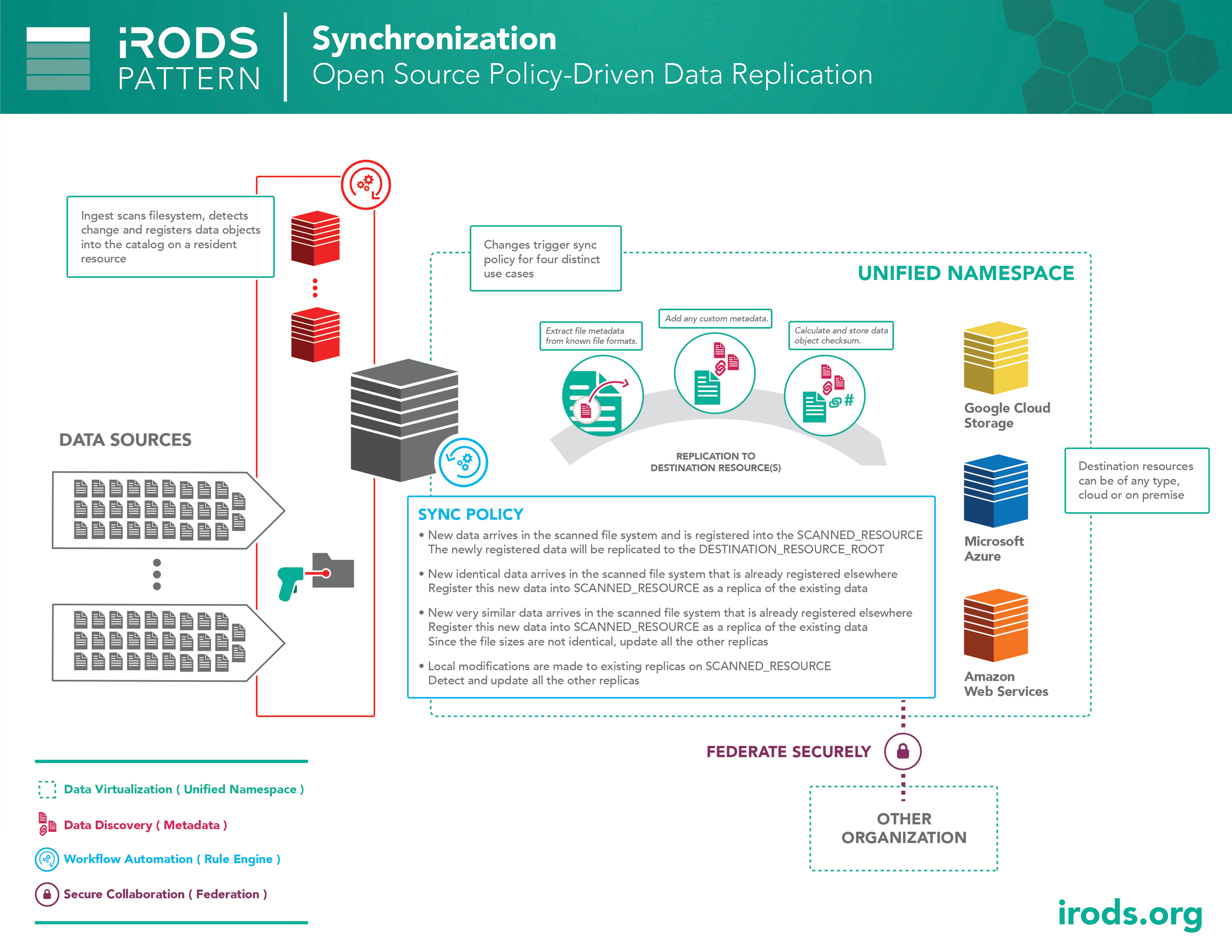
Pattern: Synchronization
iRODS is usually deployed into an environment alongside multiple other technologies. Existing filesystems may be tightly coupled with scientific instruments or legacy pipelines which are not yet ready to be directly integrated with iRODS. In these cases, iRODS can 'follow the leader' and keep its metadata catalog up-to-date by synchronizing with an existing 'source of truth'.
iRODS is usually deployed into an environment alongside multiple other technologies. Existing filesystems may be tightly coupled with scientific instruments or legacy pipelines which are not yet ready to be directly integrated with iRODS. In these cases, iRODS can 'follow the leader' and keep its metadata catalog up-to-date by synchronizing with an existing 'source of truth'.
Pattern: Data Transfer Nodes
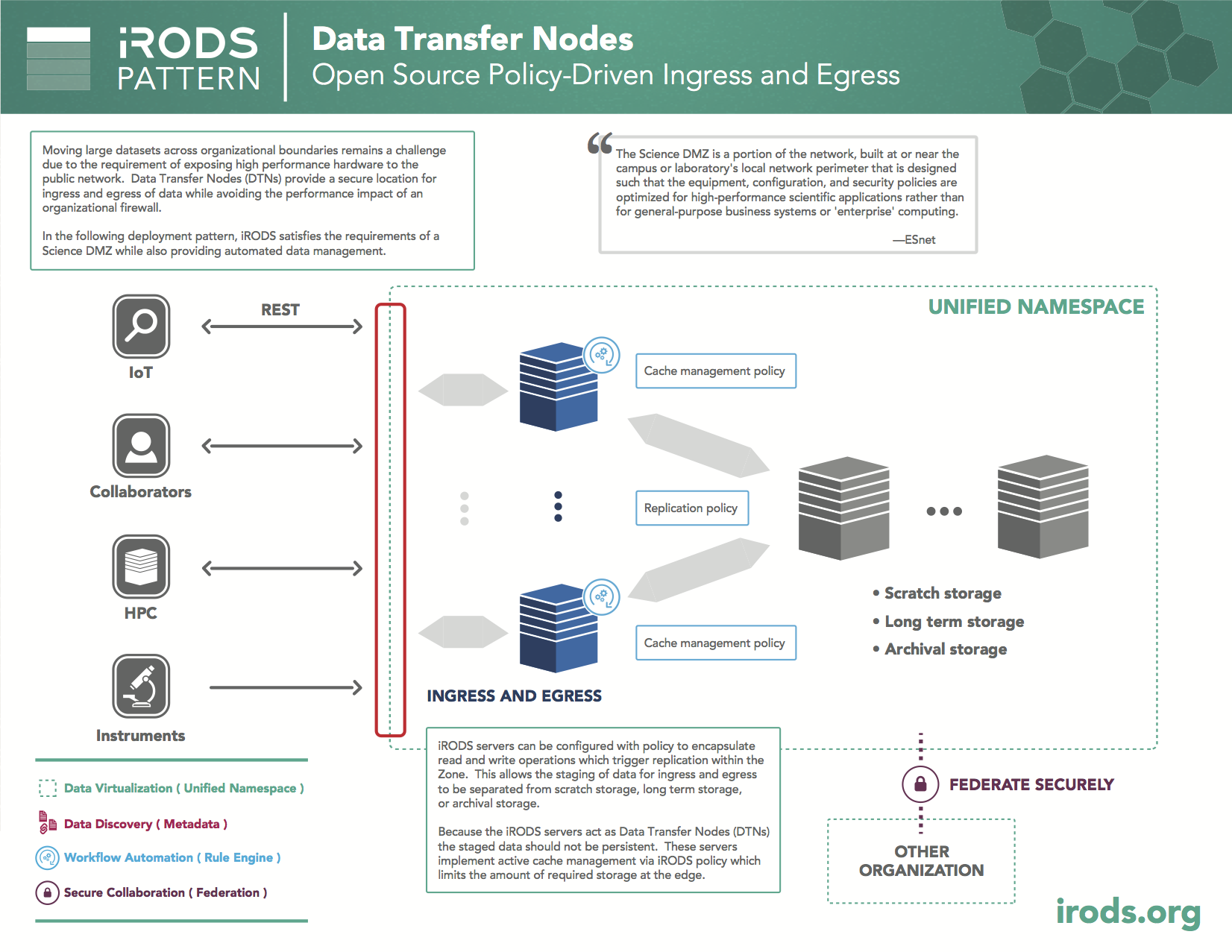
Many academic and governmental organizations have mandates to share data with one another. However, most internal networks are not designed for easy sharing with external partners. The common resulting pattern of having a DMZ, or set of machines designated as Data Transfer Nodes, provides a solution to that mandate.
Many academic and governmental organizations have mandates to share data with one another. However, most internal networks are not designed for easy sharing with external partners. The common resulting pattern of having a DMZ, or set of machines designated as Data Transfer Nodes, provides a solution to that mandate.
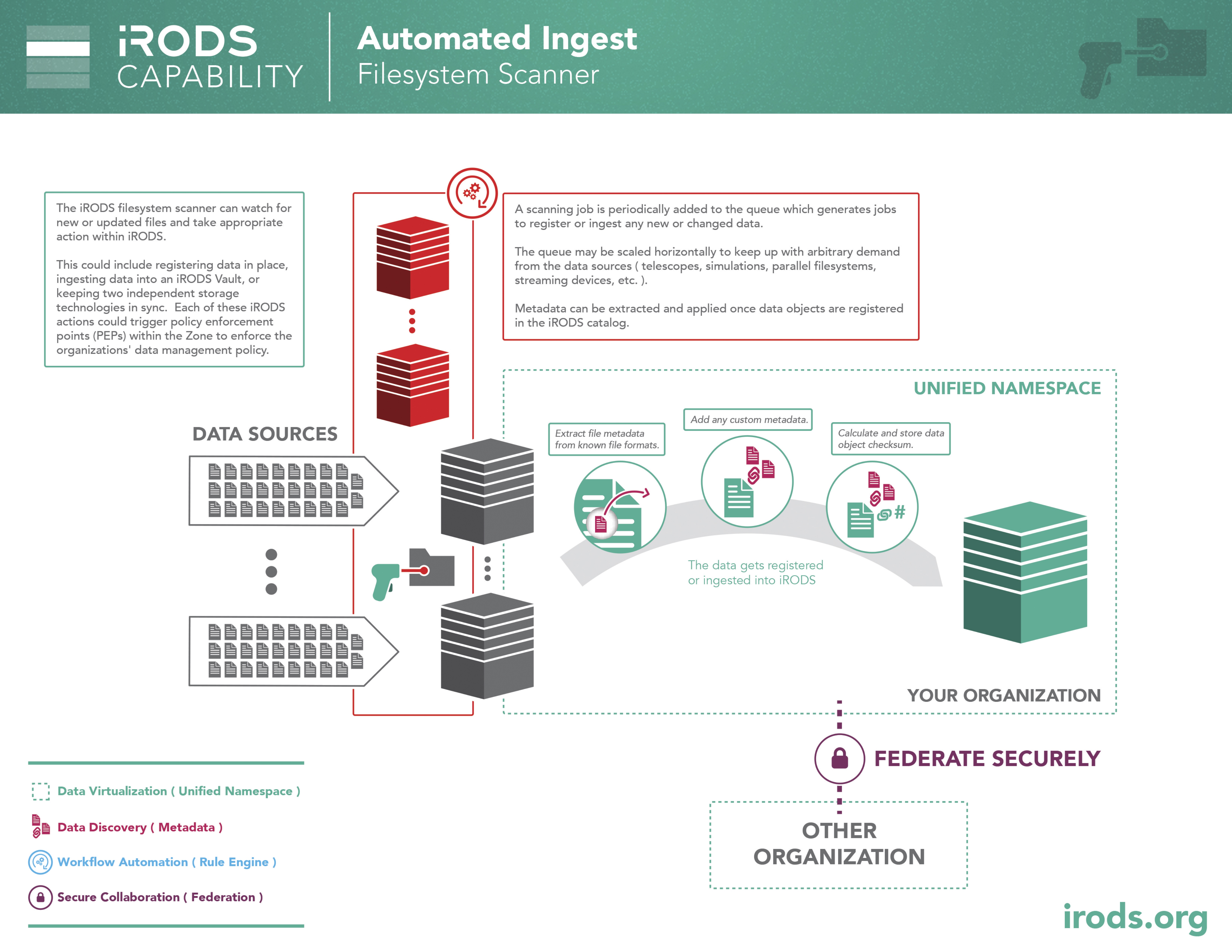
Capability: Automated Ingest - Filesystem Scanner
When an organization first discovers iRODS, it is usually true that the organization already has a lot of data in disparate storage systems. The automated ingest framework is based on Redis and Celery and can scale workers to bring large filesystems under management quickly.
When an organization first discovers iRODS, it is usually true that the organization already has a lot of data in disparate storage systems. The automated ingest framework is based on Redis and Celery and can scale workers to bring large filesystems under management quickly.
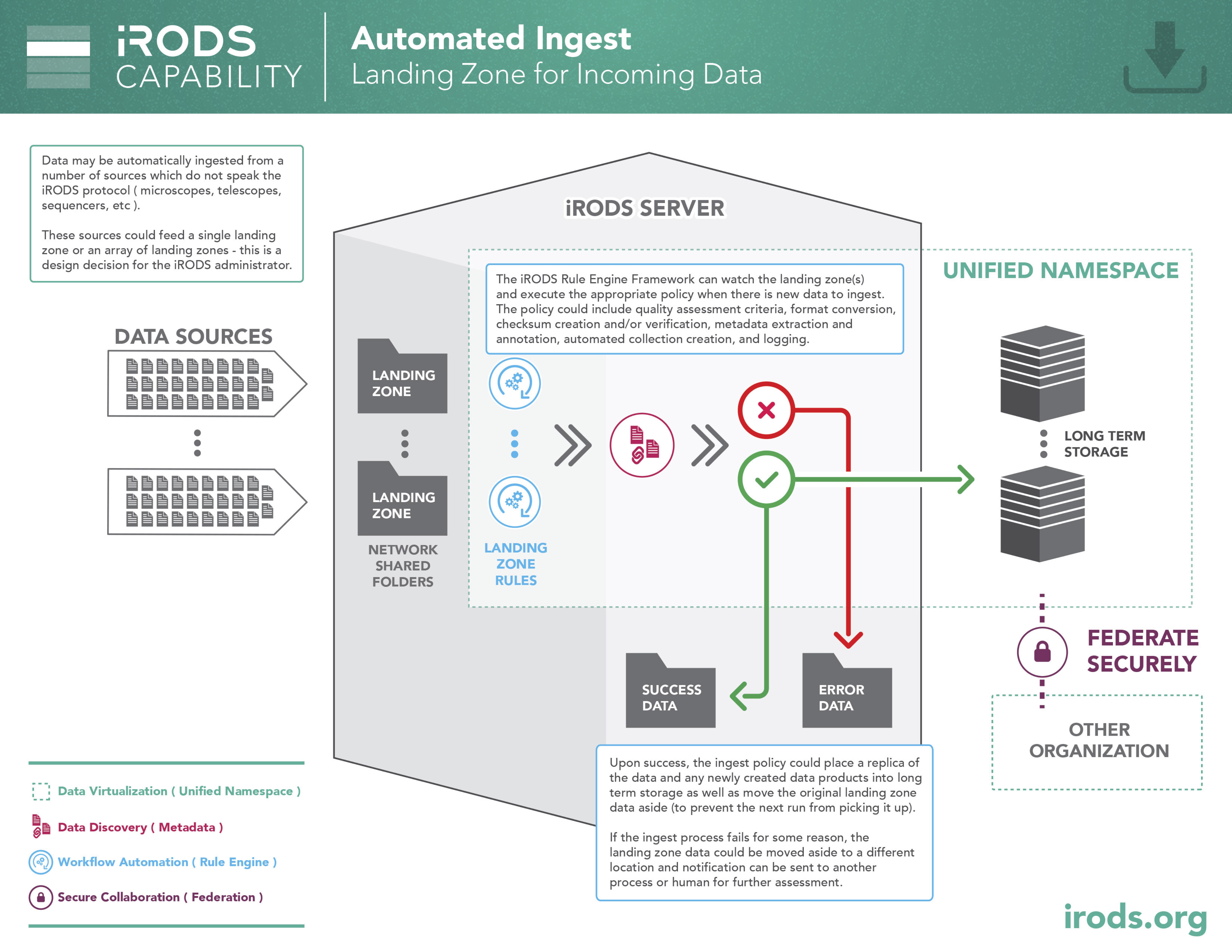
Capability: Automated Ingest - Landing Zone
iRODS is often deployed to capture products from systems that generate new files in a regular way (sequencers, telescopes, microscopes, sensor networks, etc.). The automated ingest framework can be configured to watch locations for new files and extract metadata, define manifests, and otherwise prepare them for use by the rest of the system.
iRODS is often deployed to capture products from systems that generate new files in a regular way (sequencers, telescopes, microscopes, sensor networks, etc.). The automated ingest framework can be configured to watch locations for new files and extract metadata, define manifests, and otherwise prepare them for use by the rest of the system.

Capability: Storage Tiering
The storage tiering framework provides efficient policy-driven storage utilization by automatically moving data between any number of identified tiers of storage within a configured tiering group. To define a storage tiering group, selected storage resources are labeled with metadata which define their place in the group and how long data should reside in that tier before being migrated to the next tier.
The storage tiering framework provides efficient policy-driven storage utilization by automatically moving data between any number of identified tiers of storage within a configured tiering group. To define a storage tiering group, selected storage resources are labeled with metadata which define their place in the group and how long data should reside in that tier before being migrated to the next tier.
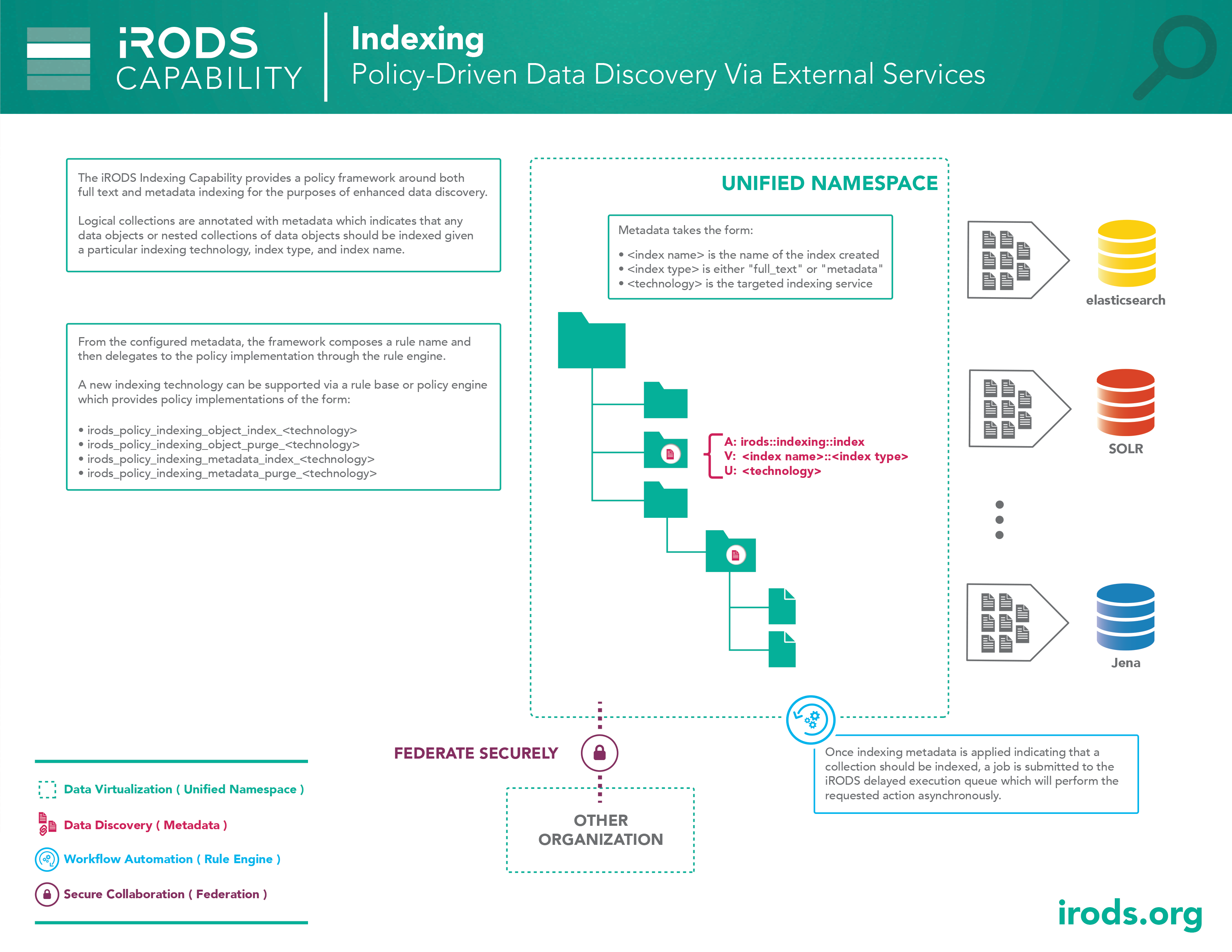
Capability: Indexing
The indexing capability provides a policy framework around both full text and metadata indexing for the purposes of data discovery. Logical collections are annotated with metadata which indicates that any data objects or nested collections of data objects should be indexed by a particular external indexing technology.
The indexing capability provides a policy framework around both full text and metadata indexing for the purposes of data discovery. Logical collections are annotated with metadata which indicates that any data objects or nested collections of data objects should be indexed by a particular external indexing technology.

Capability: Publishing
The publishing capability provides a metadata-driven policy framework for the publication of data to external services. When data is annotated appropriately, it can be protected, assigned a persistent identifier, and queued for publication to the configured catalog of record.
The publishing capability provides a metadata-driven policy framework for the publication of data to external services. When data is annotated appropriately, it can be protected, assigned a persistent identifier, and queued for publication to the configured catalog of record.
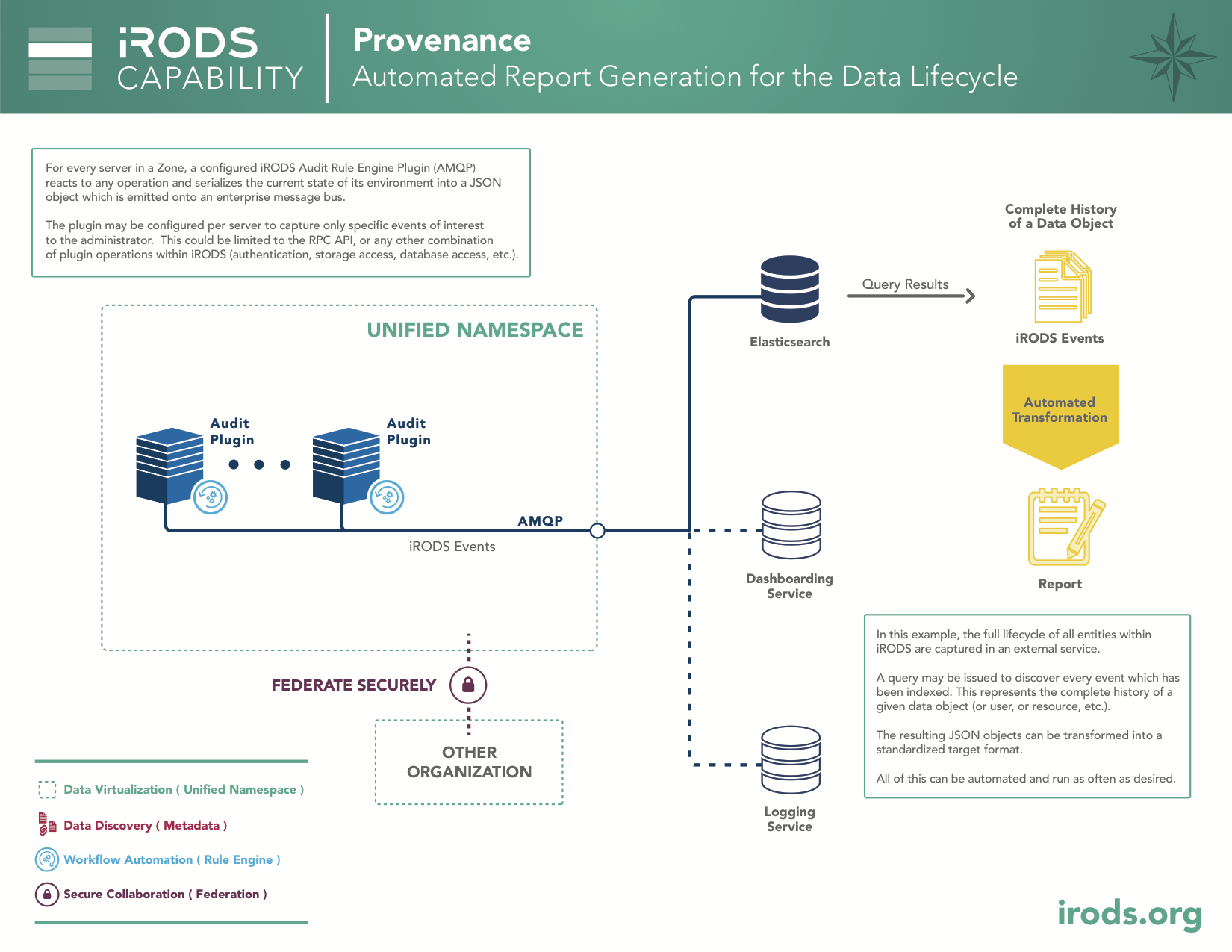
Capability: Provenance
Since every operation within an iRODS Zone can be logged with an Audit Plugin, a well-formed query can discover every event associated with a particular data object, user, or resource. The results can be formed into a standardized target format and provide automated reporting for an organization.
Since every operation within an iRODS Zone can be logged with an Audit Plugin, a well-formed query can discover every event associated with a particular data object, user, or resource. The results can be formed into a standardized target format and provide automated reporting for an organization.
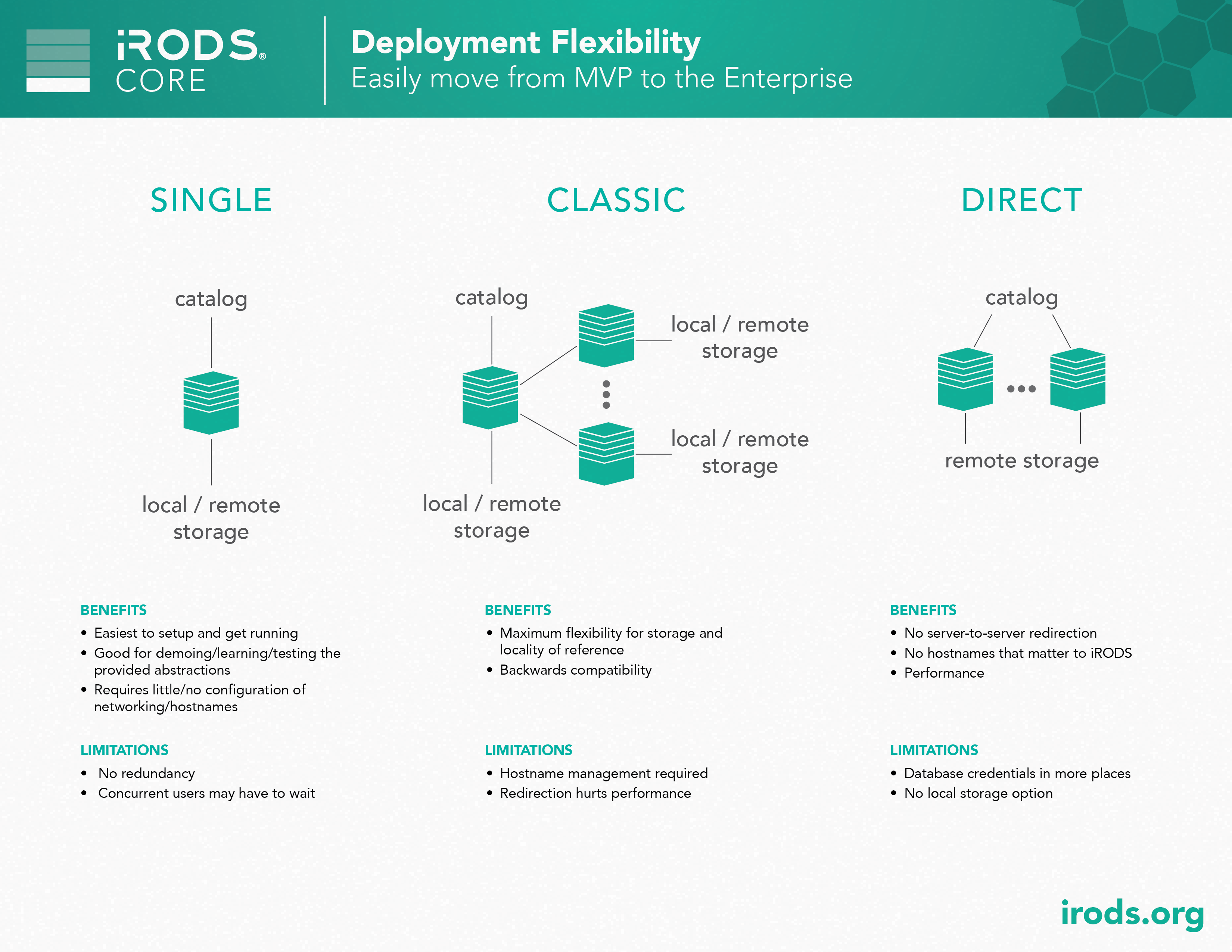
Core: Deployment Flexibility
iRODS can fit the needs of many different organizations, from simpler, smaller deployments to more complex, dynamic configurations. From local storage and compute, up to scalable, remote, and high availability systems, iRODS can provide the stable backbone of your data management platform.
iRODS can fit the needs of many different organizations, from simpler, smaller deployments to more complex, dynamic configurations. From local storage and compute, up to scalable, remote, and high availability systems, iRODS can provide the stable backbone of your data management platform.
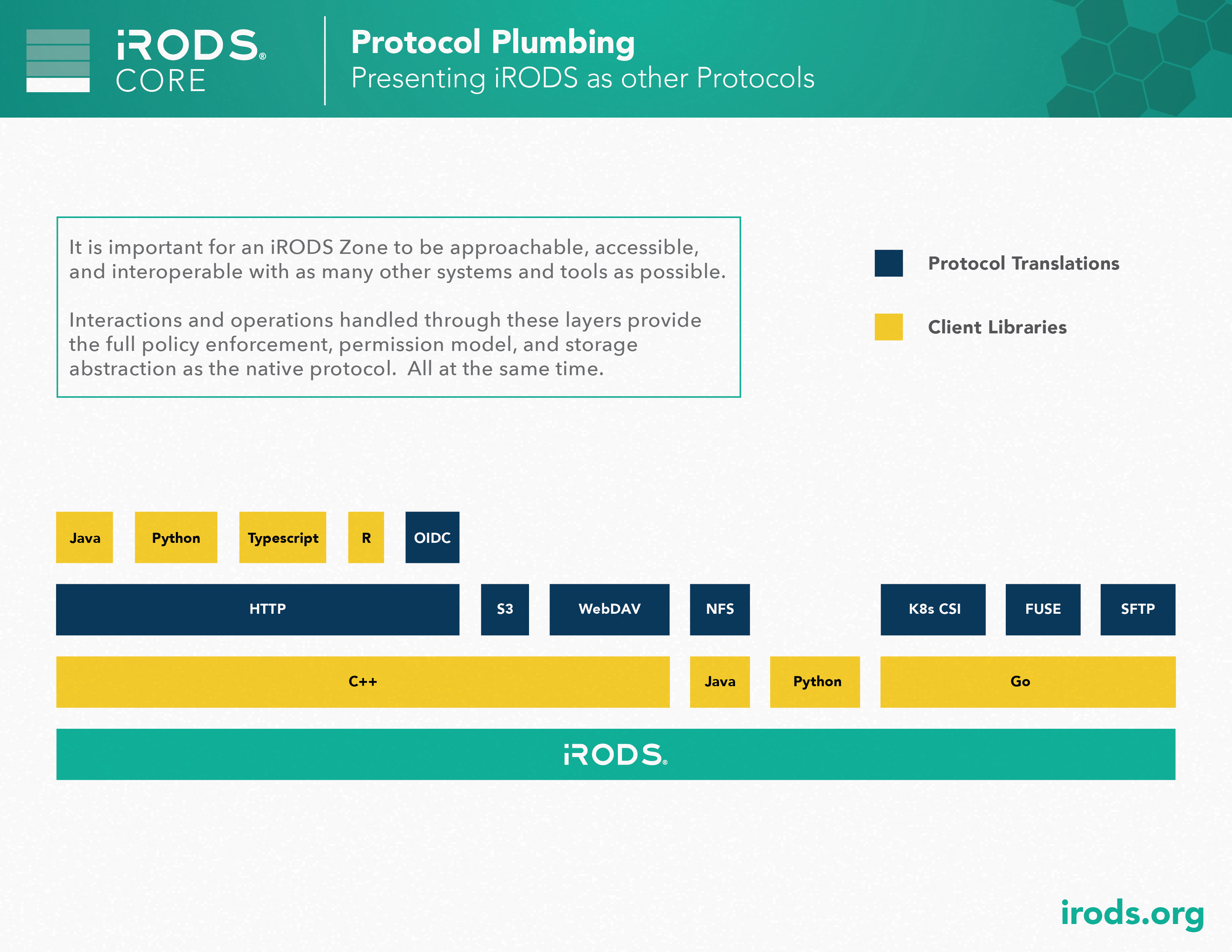
Core: Protocol Plumbing
iRODS can be accessed through multiple different client protocols at the same time. In addition to the native iRODS protocol, clients can connect through NFS, WebDAV, S3, Kubernetes CSI, FUSE, SFTP, HTTP, and OpenID Connect.
iRODS can be accessed through multiple different client protocols at the same time. In addition to the native iRODS protocol, clients can connect through NFS, WebDAV, S3, Kubernetes CSI, FUSE, SFTP, HTTP, and OpenID Connect.
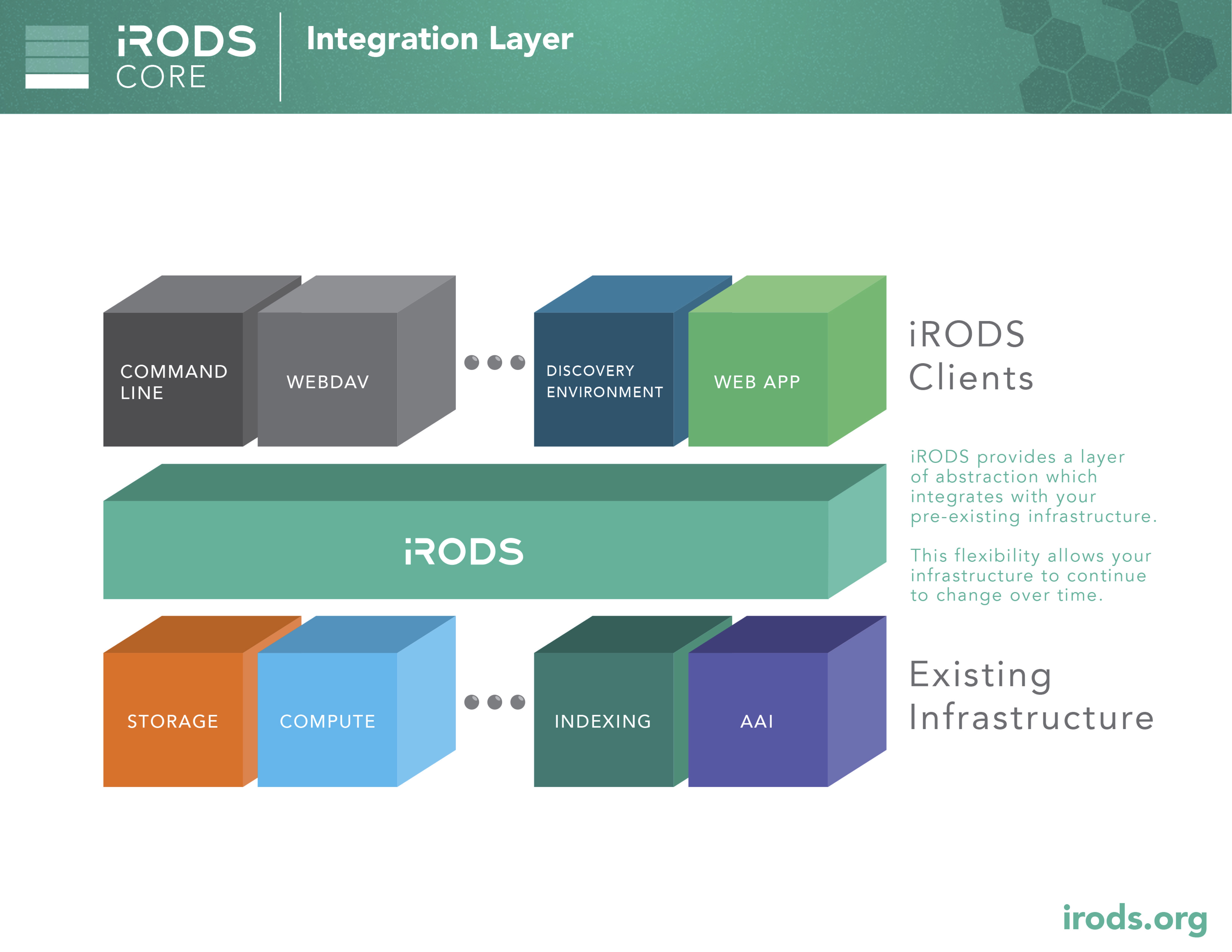
Core: Integration Layer
iRODS provides a layer of abstraction which integrates with your pre-existing infrastructure. This flexibility allows your infrastructure to continue to change over time.
iRODS provides a layer of abstraction which integrates with your pre-existing infrastructure. This flexibility allows your infrastructure to continue to change over time.
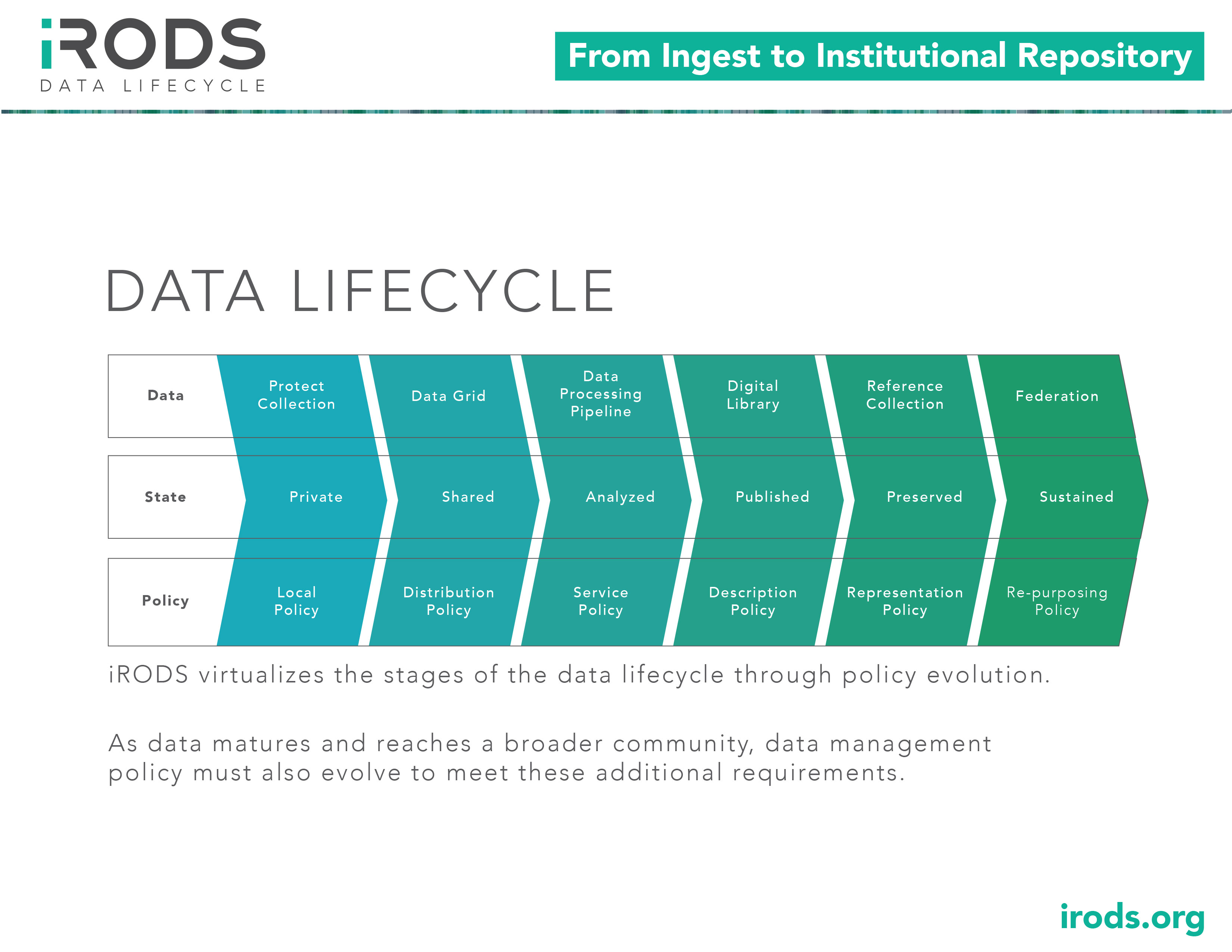
Data Lifecycle
As data matures and reaches a broader community, data management policy must also evolve to meet these additional requirements. iRODS virtualizes the stages of the data lifecycle through policy evolution.
As data matures and reaches a broader community, data management policy must also evolve to meet these additional requirements. iRODS virtualizes the stages of the data lifecycle through policy evolution.
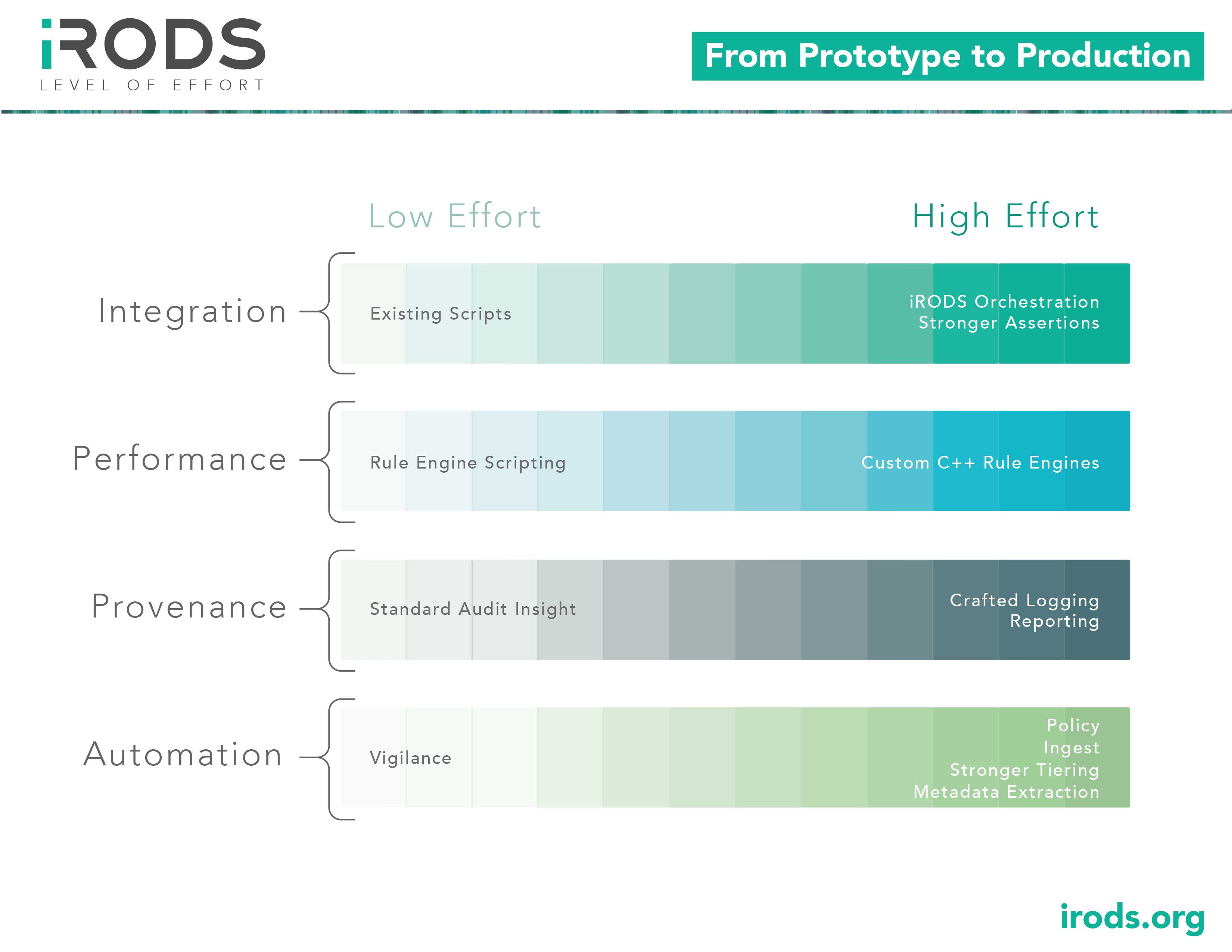
From Prototype to Production
Deploying iRODS requires making decisions about how quickly and how deeply to integrate with existing systems. The flexibility of iRODS allows for a dynamic approach that supports building confidence and trust in the software. Tighter integration and automation can lead to better performance and stronger assertions about what has happened to your data throughout its lifecycle.
Deploying iRODS requires making decisions about how quickly and how deeply to integrate with existing systems. The flexibility of iRODS allows for a dynamic approach that supports building confidence and trust in the software. Tighter integration and automation can lead to better performance and stronger assertions about what has happened to your data throughout its lifecycle.
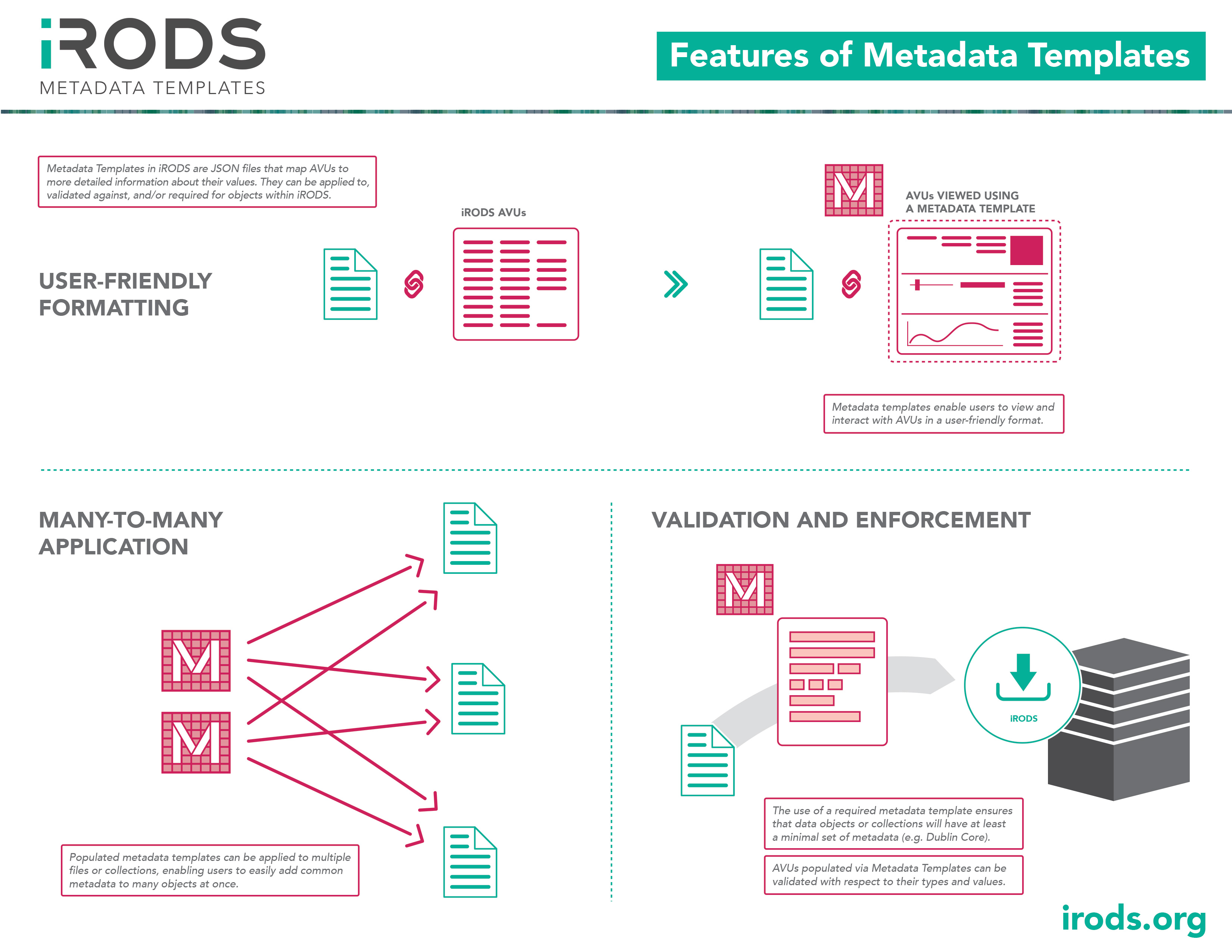
Metadata Templates
With metadata being a central part of how iRODS fosters best practices in workflows and provenance, it is also important to encourage good metadata curation. Metadata templates afford iRODS a friendly UI for specifying requirements, validation, and standardization.
With metadata being a central part of how iRODS fosters best practices in workflows and provenance, it is also important to encourage good metadata curation. Metadata templates afford iRODS a friendly UI for specifying requirements, validation, and standardization.
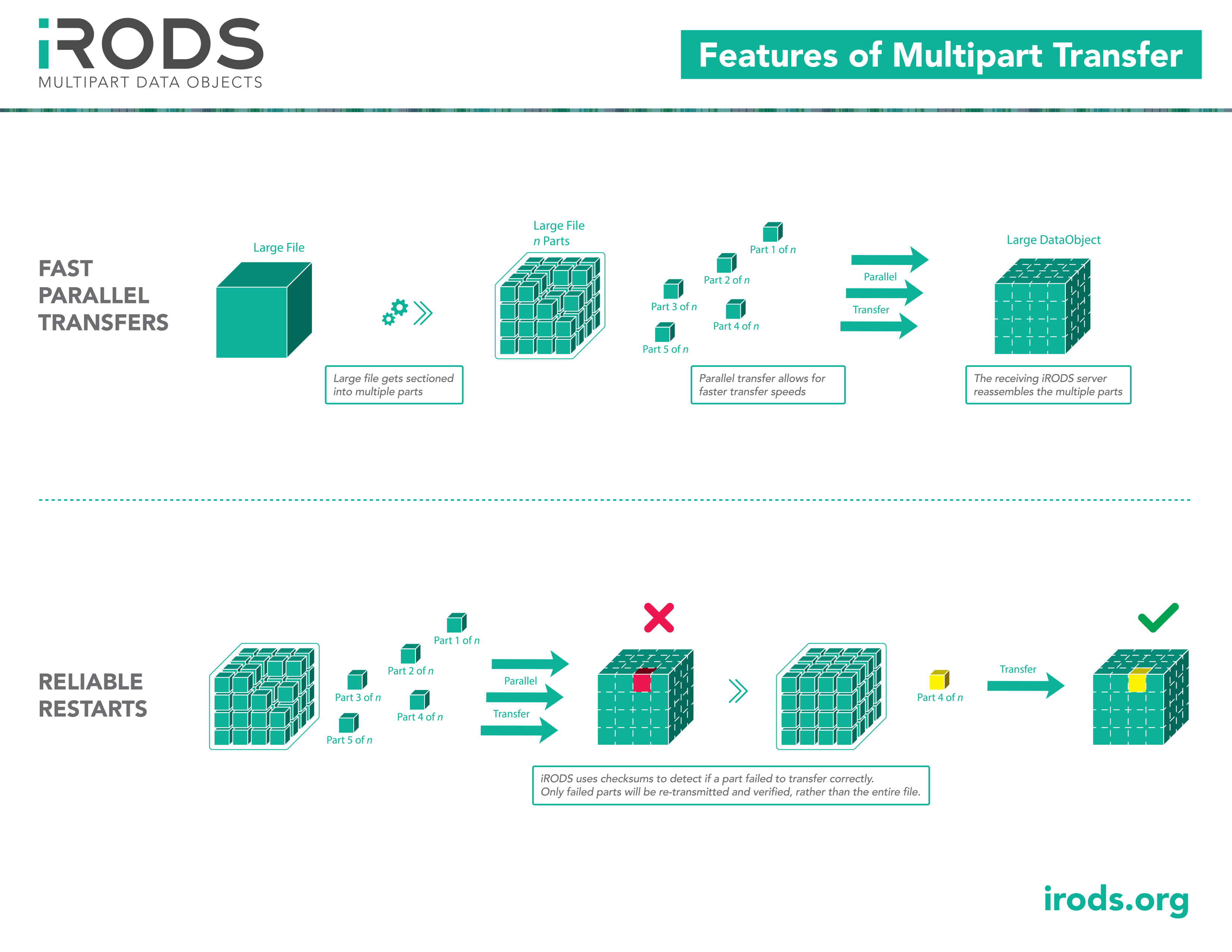
Multipart Data Objects: Transfer
An effort to improve reliability and predictability of large file transfers in iRODS, multipart data objects will improve transport speeds (parallel and/or multisource), allow for cache-free object storage plugins, and provide natural support for reliable restarts.
An effort to improve reliability and predictability of large file transfers in iRODS, multipart data objects will improve transport speeds (parallel and/or multisource), allow for cache-free object storage plugins, and provide natural support for reliable restarts.
User Group Meetings
- iRODS User Group Meeting 2025 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2024 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2023 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2022 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2021 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2020 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2019 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2018 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2017 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2016 Proceedings (PDF), (Amazon)
- iRODS User Group Meeting 2015 Proceedings (PDF), (Amazon)
Blog Posts
- Set up an iRODS server in Amazon EC2.
- Run iRODS on Docker.
- Set up an iRODS server on a virtual machine.
- Set up the WebDAV iRODS client for drag-and-drop file access.
Communication with the iRODS Community
Common Citations (iRODS 4.x)
Hao Xu, Ben Keller, Antoine de Torcy, Jason Coposky (2016) QueryArrow: Bidirectional Integration of Multiple Metadata Sources. 8th iRODS User Group Meeting, University of North Carolina at Chapel Hill. June 2016. (PDF)Reagan W. Moore, Hao Xu, Mike Conway, Arcot Rajasekar, Jon Crabtree, Helen Tibbo (2016) Trustworthy Policies for Distributed Repositories. 133pp. (publisher)
Hao Xu, Jason Coposky, Ben Keller, Terrell Russell (2015) Pluggable Rule Engine Architecture. 7th iRODS User Group Meeting, University of North Carolina at Chapel Hill. June 2015. (PDF)
Hao Xu, Jason Coposky, Dan Bedard, Jewel H. Ward, Terrell Russell, Arcot Rajasekar, Reagan Moore, Ben Keller, Zoey Greer (2015) A Method for the Systematic Generation of Audit Logs in a Digital Preservation Environment and Its Experimental Implementation In a Production Ready System. 12th International Conference on Digital Preservation, University of North Carolina at Chapel Hill. November 2-6, 2015. (PDF) (direct link)
Terrell Russell, Jason Coposky, Harry Johnson, Ray Idaszak, Charles Schmitt (2013) iRODS Composable Resources. 5th iRODS User Group Meeting, University of North Carolina at Chapel Hill. June 2013. (PDF)
Reagan Moore, Arcot Rajasekar, Hao Xu (2015) DataNet Federation Consortium Preservation Policy Toolkit. 12th International Conference on Digital Preservation, University of North Carolina at Chapel Hill. November 2-6, 2015. (PDF) (direct link)
Arcot Rajasekar, Terrell Russell, Jason Coposky, Antoine de Torcy, Hao Xu, Michael Wan, Reagan W. Moore, Wayne Schroeder, Sheau-Yen Chen, Mike Conway, Jewel H. Ward (2015) The integrated Rule-Oriented Data System (iRODS 4.0) Microservice Workbook. 248pp. (PDF) (amazon)
Presentations
-
Building the iRODS Consortium, All Things Open: October 2014 (pdf)
Dan Bedard, iRODS Consortium -
Data Management Using iRODS, Fundamentals of Data Management: September 2014
Albert Heyrovsky, Edinburgh Parallel Computing Center (EPCC) -
Managing Next Generation Sequencing (NGS) Data using iRODS, ICG-9: September 2014
Dan Bedard, iRODS Consortium
Papers and White Papers
-
Policy-Based Data Management: The Future of Reproducible, Data-Driven Research
Dave Fellinger, DataDirect Networks; Reagan W. Moore and Hao Xu, University of North Carolina at Chapel Hill
American Laboratory. March 18, 2015 -
Data Intensive processing with iRODS and the middleware CiGri for the Whisper project
Xavier Briand, ISTerre, & Bruno Bzeznik, Universite Joseph Fourier -
Control Your Data
RENCI and iRODS Consortium -
Using an Integrated Rule-Oriented Data System (iRODS) with Isilon Scale Out NAS (external link, emc.com)
EMC -
Principles of Archival of Digital Assets
John Burns, Archive Analytics -
Concepts in Distributed Data Management, or DICE History of the DICE Group
Moore, et al.; UNC, UCSD -
Composable Resources Paper, iRODS User Group 2013: March 2013 (279kB, PDF)
Russell, et al.; RENCI -
Hardening iRODS for an Initial Enterprise Release (E-iRODS), iRODS User Group 2012: March 2012 (poster)
Russell, et al.; RENCI -
Towards a Theory of Digital Preservation, IJDC, Issue 1, Vol 3, June 2008
Reagan W. Moore
Media & more ...





